Evals Are a Feedback Loop, Not a Score
What the best agent teams in 2026 know about measuring their systems

Evals Are a Feedback Loop, Not a Score
Most teams I talk to treat evals like a test suite. You build the agent, write some tests, watch it pass them, ship it. Done.
That model is wrong — and it's why so many agents plateau after the first sprint.
Evals are not a scoreboard. They're a training signal. Your agent will hill-climb on whatever you give it to optimize for. If your evals don't encode the real behavior you want — not the proxy, not the offline approximation, the actual thing your users need — you'll ship an agent that passes your tests and fails your users.
Here's what I've learned building agents in production, and what the field is converging on in 2026.
1. Evals are the substrate
"Evals are the substrate that determines what your agent does in production. They're training data for agents because we literally fit our agent to pass Evals via hill-climbing algorithms and human edits to pass failure modes. Once you get your agent into users hands, the eval generation loop compounds."
The word "substrate" is doing real work here. Not tests. Not benchmarks. Substrate — the medium in which something grows.
Your agent grows to fit its evals. Every prompt edit, every tool tweak, every model swap — you measure the result against your evals and keep what passes. That's hill-climbing. It's happening whether you've named it or not.
The question isn't whether you're hill-climbing. It's whether you're climbing the right hill.
I've built systems where the eval was a holdout dataset — historical labels, frozen in time. We got very good at predicting the past. The metric looked great. Production results were flat. The hill we climbed wasn't the hill that mattered.
The gap between "passes offline evals" and "works in production" is exactly the gap between the frozen labels you have and the live behavior you actually care about. A user who asks a follow-up because the first answer was wrong — that's signal. A document that fails to extract correctly — signal. A recommendation that gets ignored — signal. None of those were in my eval set at first.
The moment you wire those production signals back into your evals, the hill changes shape. And the agent starts improving at what you actually care about.
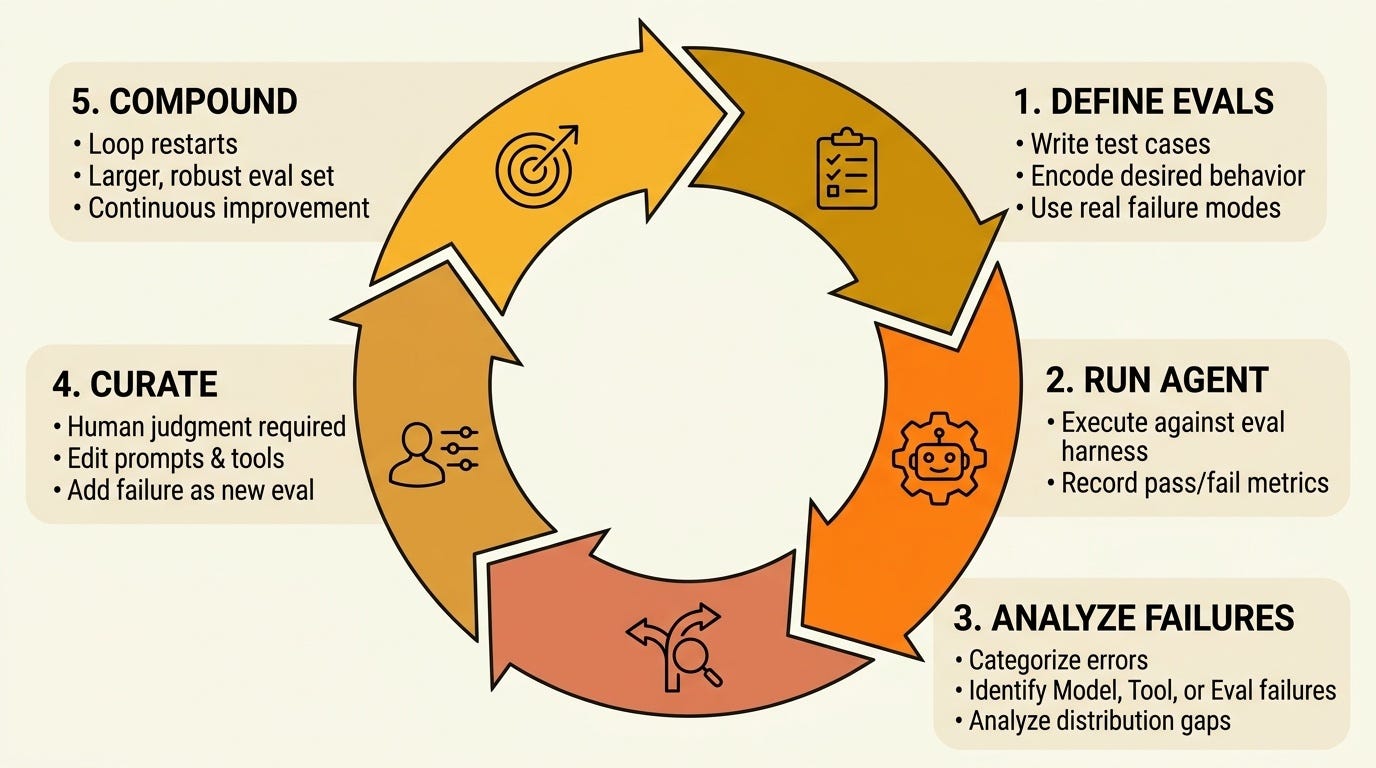
2. Hill-climbing is the mechanism
"This harness optimization process is becoming much more agent driven with humans reviewing and curating evals/rewards to hill climb on. Evals are a moat and thus data to produce evals is a moat. Especially true for vertical agent companies. This is because agents can fit to most Eval sets today."
Here's the operational picture: you have an agent, you have a harness — the runtime, tools, prompts, skill definitions. You run the agent against your eval set. Some pass, some fail.
For failures, you do one of three things:
Edit the prompt
Change a tool definition
Add the failure as a new eval case
Then you run again. That loop — run → fail → edit → run — is hill-climbing. The harness is the surface you're optimizing over.
What I've found is that curation is the hardest part. It's easy to write a hundred evals. It's hard to write evals that are:
Representative of what users actually encounter (not what you imagine they encounter)
Sensitive enough to distinguish genuinely good responses from superficially good ones
Robust enough not to be gamed by surface changes
In document processing systems I've worked on, the best evals came from the failure queue — messages that failed in production, got stuck, or produced wrong output. Those aren't hypothetical edge cases. They're real ones. Each is a new data point about exactly where the agent breaks.
That failure queue is your eval generator, if you treat it as one.
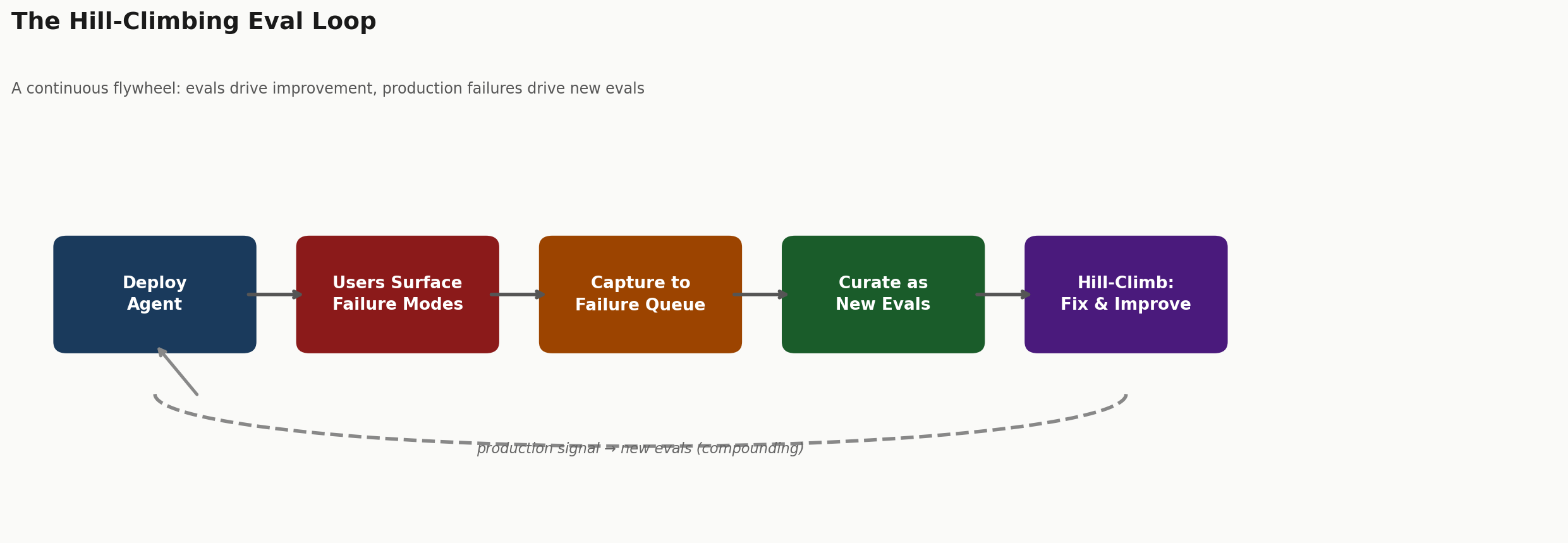
3. The compound loop
"new goal unlocked: grind so everyone forgets what a harness is and they just tell us what their agent needs to do, and we just chef it all together for them (harness + evals + envs + infra + observability + self-improvement + good-vibes)"
The vision here is compounding. Not just "evals improve the agent" — evals improve the agent → the improved agent reaches users → users surface new failure modes → those become new evals → the agent improves again.
Once this loop is running, it's hard to stop. Early on you're writing evals manually, dogfooding your own product to find where it breaks. Later, production data does most of the discovery for you. The best teams I've seen have an almost-automated pipeline from "something went wrong in prod" to "there's a new eval case in the backlog."
The key enablers:
Observability: you have to be able to see failures. Structured logging with correlation IDs, run IDs, case IDs. If you can't query "show me all the cases where the agent's output was flagged," you can't close the loop.
Categorization: not all failures are equal. Some are model failures. Some are tool failures. Some are eval failures (the eval expected the wrong answer). Knowing which is which tells you where to intervene.
Low friction to add evals: if adding a new eval case takes an hour, you won't do it for every production failure. If it takes a minute, you will. This is infrastructure, not process.
The "chef it all together" framing is the right end state: a team that describes what the agent should do, and has infrastructure that measures whether it does that thing, surfaces the gaps, and closes them. The eval harness is the product, not the afterthought.
4. Gall's Law: earn your complexity
"Gall's law: 'a complex system that works is invariably found to have evolved from a simple system that worked.' Also very relevant to agent systems. Most teams are trying to jump straight to autonomous complexity before they have evals, observability, or feedback loops in place. 2026 is the year of evals."
The agent teams I've seen struggle have almost always skipped the observable-simple-system phase. They built an orchestrator with five subagents, a memory layer, and tool use on day one. When it breaks — and it breaks — there's no way to tell which part failed. The eval is "the user seemed unhappy." That's not a training signal; it's a symptom.
My rule: before you add complexity, make sure you can see what's happening. Traffic interception, request logging, structured output validation, human review queues — pick your poison, but have something. A simple agent with good observability will outrun a complex agent with none. You can improve what you can measure. You can only guess at what you can't.
The practical implication: your first eval should be manual. A human reviewing the agent's outputs and labeling them good or bad is a valid eval harness. It's slow, it doesn't scale, but it forces you to articulate what "good" looks like. That articulation is the hard part. Everything else is tooling.
Complexity earns its place when the simple system is working and you know exactly which constraint it's hitting. Not before.
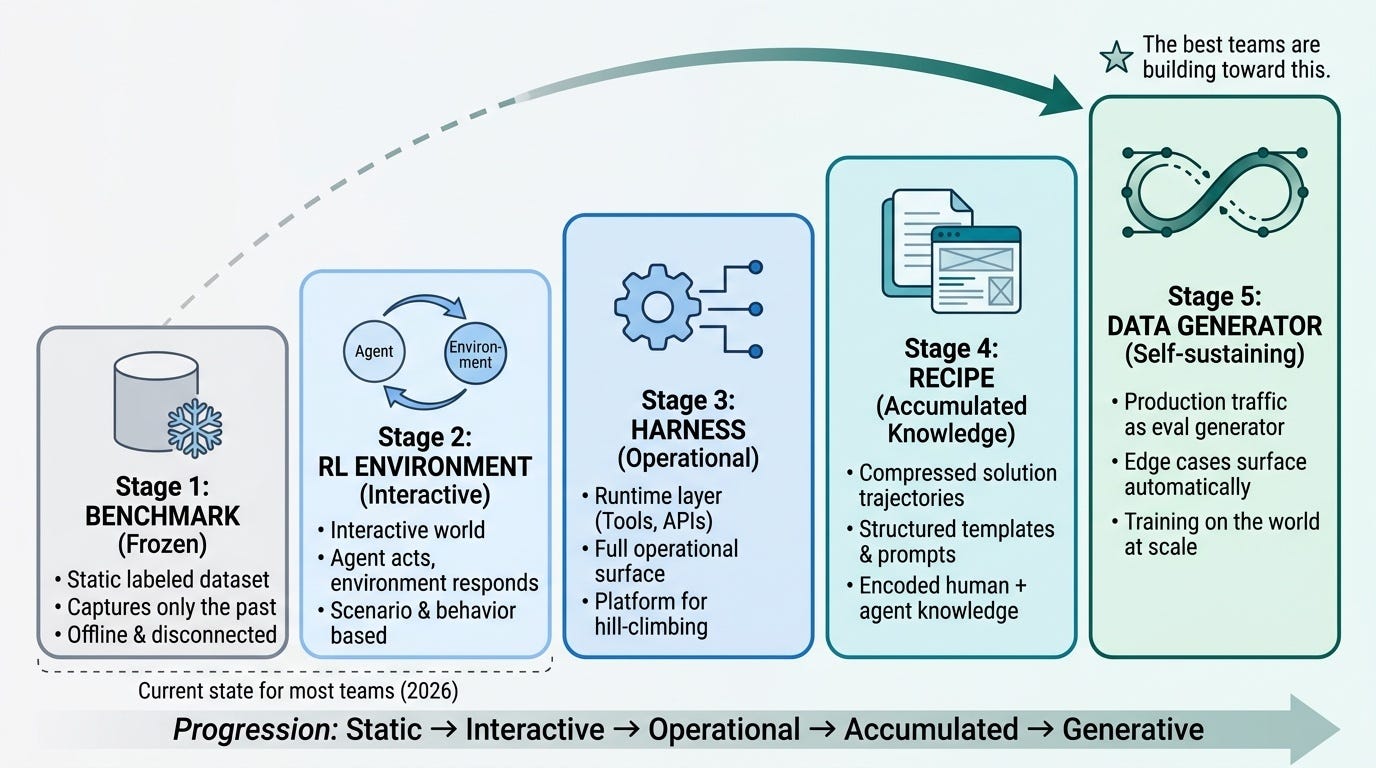
5. The frozen benchmark trap
"A benchmark is a frozen view of a solvable world. An RL environment is the same world made interactive. A harness is the runtime that lets agents act in it. A recipe is a compressed solution trajectory. A data generator is the world sampled at scale."
This mental map is the clearest framing I've seen of where evals need to go.
Most agent teams are at level 1: frozen benchmark. A test set, a score, a ship decision. The problem is that this test set was assembled from a distribution of inputs that existed at a point in time, labeled by people who had to make assumptions about what the right answer was. It doesn't capture the full distribution of what the agent will actually encounter. It captures what someone had time to label.
The unlock is level 2: interactive environment. Instead of "predict the right answer for these labeled inputs," it's "act in this environment and we'll observe what happens." The eval stops being a static check and starts being a simulation of real usage. Failures are now observable behaviors, not output mismatches.
From there, the natural progression:
Harness: you build the runtime around the environment. Tools, skills, APIs, prompts — the harness is the surface the agent operates on, and the surface you optimize over.
Recipe: accumulated knowledge compressed into structure. A wireframe template, a skill definition, a system prompt that encodes what good behavior looks like. Recipes are what you get when a domain expert and an agent engineer work together long enough.
Data generator: at scale, the world generates evals for you. Production traffic, user interactions, edge cases you didn't anticipate — they surface continuously and become the raw material for the next round of eval curation.
Most teams in 2026 are at level 1. The best teams are building toward level 5. The distance between them is compounding every month.
6. Evals as measurement infrastructure
"Evals, benchmarks, and RL environments. Measurement infrastructure that decides whether agents are safe to ship."
"Measurement infrastructure" — not tests, not QA, infrastructure — is the right framing.
Infrastructure implies:
Built once, used many times
Maintained and improved as the system evolves
A prerequisite for everything that depends on it
Skimping on it creates debt that compounds
When I look back at agent systems I've built that stayed healthy versus ones that rotted quickly, the difference is almost always measurement infrastructure. Systems with eval harnesses improved iteratively. Systems without froze at their initial performance level because there was no way to know if a change was an improvement or a regression.
The "moat" framing is real. If your eval set encodes all the good behavior your agent needs to exhibit — edge cases, difficult inputs, real failure modes from production — that set is genuinely hard to replicate. It took real production data and real failure events to build. A competitor starting from scratch doesn't have that signal. They have benchmarks. You have signal.
This is why measurement infrastructure compounds in value over time, not just in the short run.
7. The human layer: who actually does this work
"Companies need help figuring out which models will work best for their workflows, they need extensive evals setup often, they need change management support for workflows, they need to get their data setup for the agents, and constant tuning of the agentic system for their process."
The eval harness doesn't build itself. Someone has to:
Watch production for failures
Translate failures into eval cases
Run the hill-climbing loop
Know when the metric is being gamed versus genuinely improving
Change the eval when the eval is wrong
That's a human job. And it's one of the most technically demanding jobs in AI right now — precisely because it sits at the intersection of domain knowledge, engineering, and judgment about what actually matters.
The best AI teams I've worked alongside treat eval curation as a primary engineering discipline. Not something that happens after the "real work" is done. The eval harness is the real work. It's the system that makes the agent improvable. Everything else — the model choice, the infrastructure, the UI — is replaceable. The evals, and the process for generating them, aren't.
The practical implication: whoever is closest to production failures should have a direct line to your eval set. Whether that's a data scientist triaging a failure queue, a product manager reviewing user feedback, or an engineer watching structured logs — the signal is there. The question is whether you've built the pipeline to capture it, and whether the person who sees the failure can turn it into a new eval case in under five minutes.
If not, that's the first thing to fix.
Close the loop
The teams winning on agents in 2026 aren't the ones with the best models. Models are increasingly commoditized. They're the teams with the best eval infrastructure — the ones who've turned production failures into training signal, moved from frozen benchmarks to interactive environments, and made "add an eval" a reflex rather than a project.
Hill-climbing never stops. The question is whether you're climbing the right hill, and whether your instrumentation is sensitive enough to tell.
Start with one eval. Make it manual. Make it honest. Wire it to something real — an actual failure mode, an actual user scenario your agent encountered yesterday. Then close the loop.
The compounding starts when you do.