Flavor Neo: a leader/worker/verifier loop for cheaper, more correct agent runs
How I split judgment from labor across model tiers, and why the verifier matters more than any worker

Most people run one agent, one context window, one shot at a time. That works until the task is big enough that a single agent either runs out of context digging through the codebase, or burns your best model's tokens on grunt work a cheaper model could handle.
I run something different: a fixed harness called Flavor Neo. It is not a model or a framework. It is a loop structure that turns "the strongest model I have access to" into a leader that plans, delegates, and judges, while cheaper models do the scanning. It lives as a single SKILL.md file you drop into your agent's skills directory. No dependencies, no runtime, no daemon; just a protocol your agent follows when you say "flavor-neo" or "neo audit."

The problem it solves
Here's what happens when you throw a big task at a single agent:
Token waste on grunt work. Your 5 USD/MTok Opus model spends 80% of its context scanning files for stale dates and mismatched names. A 1 USD/MTok Haiku or Gemini Flash model does that work equally well.
Self-grading. The agent implements a fix, then evaluates its own fix. It shares its own blind spots. If it misunderstood the requirement, it will misunderstand the check too.
Runaway loops. Without a hard stop, a revise cycle burns tokens indefinitely. I once watched 40 USD disappear on a loop thrashing between two conflicting fixes.
Flavor Neo addresses all three by separating who does what and who checks whom.
The shape of the loop
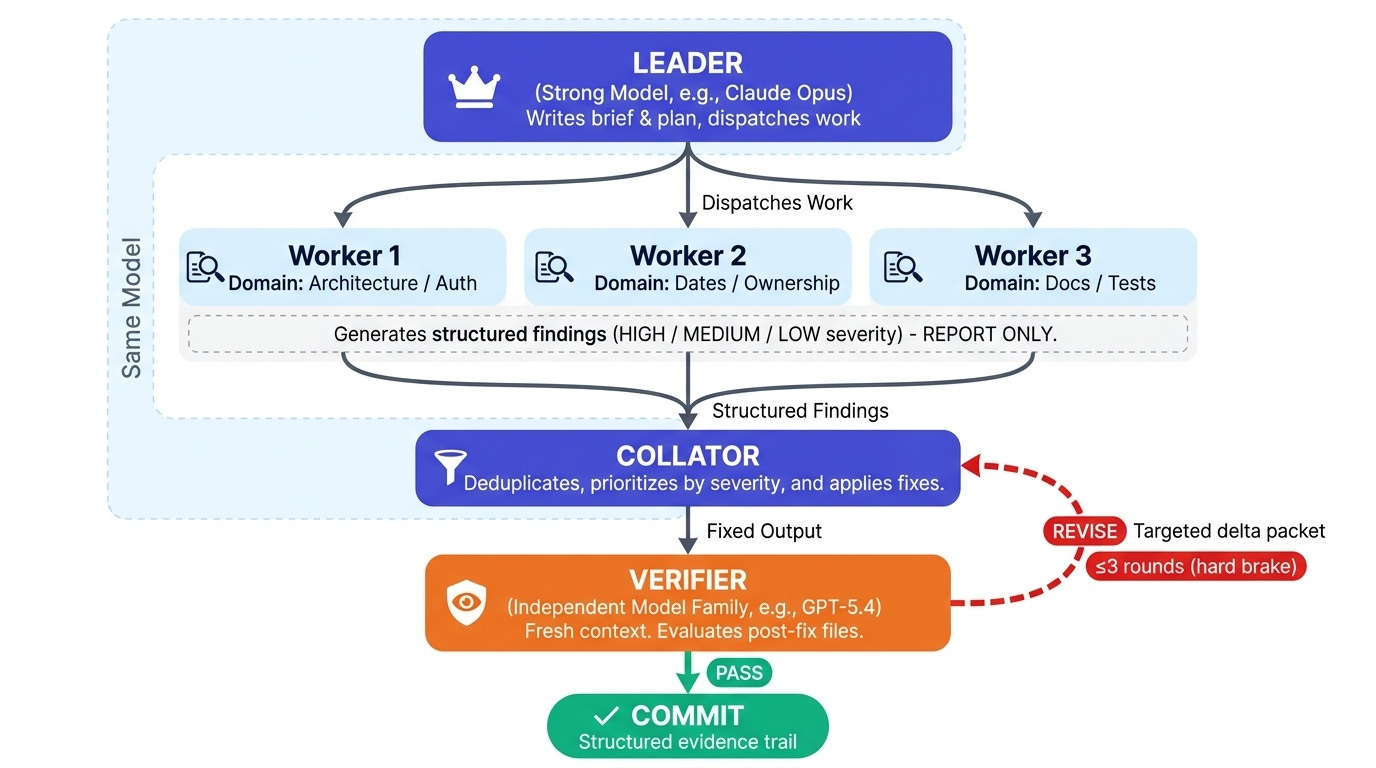
The leader spends premium tokens on judgment: planning, delegation, review, deciding what "done" means. Workers spend cheap tokens on volume: scanning files for contradictions, running searches, reporting what they find. The verifier matters more than any single worker. It is the one role that is not allowed to grade its own homework.
Why a different model family for the verifier
Same-model verification has correlated blind spots. If Claude misunderstands a requirement during implementation, Claude-as-verifier will likely misunderstand it the same way. Routing the verifier through GPT-5.4 (or Gemini, or whatever is available that is not the worker's model) breaks this correlation. The verifier gets only the goal contract and the candidate result, never the implementer's reasoning, so it evaluates the output, not the rationale.
The five rules
Rule 1: don't use the full loop by default
Before dispatching workers, I ask whether the task needs Flavor Neo at all:
Under 30 minutes, one file, low ambiguity → just do it directly. No orchestration needed.
Simple implementation but correctness matters → skip the workers, but still run an independent verifier as a one-off check.
Need a specialist tool/model but no real parallelism → one worker plus a verifier, but this is lightweight delegation, not the full loop.
2-3 genuinely independent scan lanes, or the task is long-horizon and unattended → this is where Flavor Neo earns its keep. The full loop with 2-4 parallel workers, a collator, and a cross-model verifier.
The overhead of coordination (context duplication, summarization loss, merge conflicts) is real. If setting up lanes costs more than doing the task directly, don't fan out. Most requests don't need the full machine. About 70% of my daily work stays below the threshold. The full Flavor Neo loop triggers maybe twice a week.
Rule 2: every run starts with a goal contract
No contract, no verification target. Every dispatch states:
The outcome: what specific thing should be true when this is done.
The definition of done: not "looks good" but "file X contains Y, test Z passes, URL responds with status 200."
The proof requirement: a test result, a URL, a screenshot, a diff. Something inspectable, not a claim. Workers cannot self-report success; they must produce an artifact the verifier can check.
The brake: max rounds, and an instruction to report a blocker honestly rather than invent success.
This is the contract that flows through the entire loop. The verifier checks against the contract, not against vibes.
Rule 3: lanes tile the goal completely, with zero overlap
If two workers touch the same files, that's not parallelism; it's a merge conflict waiting to happen. Lanes are split by deliverable (an inspectable artifact with a done-state), never by activity like "research" or "improve," because only a deliverable can carry a proof requirement.
In practice, I split by domain:
Architecture / Auth lane: scans API contracts, auth flows, schema mismatches across
src/api/,src/auth/,openapi.yamlDates / Ownership / Blockers lane: scans for stale dates, wrong owners, resolved blockers still listed in
README.md,CODEOWNERS, project docsDocs / Tests / Staleness lane: scans for outdated docs, dead tests, claims that contradict code in
docs/,test/, inline comments
Each worker gets its file list, its focus domain, and its output format. Workers report findings as structured items with severity (HIGH / MEDIUM / LOW). They do not fix anything; report only. The strong model does the fixing.
Rule 4: the verifier is a different model, fresh context, no self-grading
The single most important rule in the whole system. An implementer that also verifies its own work shares its own blind spots. The verifier gets:
The original goal contract
The candidate result (the actual files, post-fix)
Nothing else: no worker reasoning, no collator notes
It returns exactly one of:
C-01: PASS
C-02: FAIL — date in README still says 2025, file shows 2026 in git log
C-03: PASS
...
NEW FINDINGS: Section 4.2 claims "no Docker required" but Dockerfile exists at root
VERDICT: REVISE (delta packet: fix C-02, address new finding)The verifier's output format is rigid on purpose. PASS or REVISE with specific findings. "Looks mostly good" is a non-answer that lets problems through.
Rule 5: a hard brake, always
Feedback loops without damping oscillate or run forever. The skill specifies one hard constraint: ≤3 rounds. If the verifier returns REVISE three times, the loop stops and reports what's unresolved. Most runs converge in 1-2 rounds. After the brake trips, unresolved items go into the commit message's "Still open" section for human review; they are not silently dropped.
Without a brake, a revise loop is a machine that bills you silently while never converging. I learned this the expensive way.
A real example: documentation audit
Last month I ran Flavor Neo against a project with ~40 markdown files that had drifted over six months of active development. Architecture docs referenced services that had been renamed. Dates were wrong. The CODEOWNERS file listed people who had left.
Setup (Leader, ~2 minutes):
Split into 3 lanes. Gave each worker its file list and scan criteria. Total leader tokens: ~3,000.
Workers (parallel, ~4 minutes):
Three explore agents ran simultaneously on Claude Haiku 4.5 (1 USD/MTok input, 5 USD/MTok output). Each scanned its domain and reported structured findings:
Worker A (architecture lane, 12 files): 8 issues found, ~4,000 input tokens + ~1,200 output tokens
Worker B (dates/ownership lane, 15 files): 12 issues found, ~5,500 input + ~1,800 output
Worker C (docs/tests lane, 13 files): 6 issues found, ~4,500 input + ~1,000 output
Representative findings:
FINDING: docs/architecture.md §3 says "auth-service handles login"
but src/gateway-v2/routes/auth.ts has owned this since commit a3f2e1 (March)
Severity: HIGH
FINDING: CODEOWNERS line 14 lists @cheneva for /src/pipeline/
but cheneva's last commit was November; @ucalyptus owns this now
Severity: HIGH
FINDING: README.md "Last updated: 2025-11" but 38 files changed since then
Severity: MEDIUMTotal worker cost: ~14,000 input tokens × 1 USD/MTok + ~4,000 output tokens × 5 USD/MTok = ~0.03 USD.
Collation (Leader, ~3 minutes):
Deduplicated: 5 findings were flagged by multiple workers. Prioritized: 14 HIGH, 4 MEDIUM, 3 LOW. Applied fixes to all HIGH and MEDIUM items. Skipped LOW. Leader token cost at Opus rates (5 USD/MTok input, 25 USD/MTok output): ~4,000 input + ~3,000 output = ~0.10 USD.
Verification (GPT-5.4, ~5 minutes):
Verifier confirmed 16 fixes, caught 2 that introduced new inconsistencies (I had updated a service name in the architecture doc but missed a reference in the onboarding guide), and found 1 issue all three workers had missed. Returned REVISE with a 3-item delta packet. Verifier cost at GPT-5.4 rates (2.50 USD/MTok input, 15 USD/MTok output): ~6,000 input + ~1,500 output = ~0.04 USD.
Round 2 (~3 minutes):
Applied the delta. Verifier returned PASS. Round 2 cost: ~0.03 USD.
Total wall-clock: ~17 minutes. Total cost: ~0.20 USD.
For comparison, running the same task through a single Opus context window would require loading all 40 files (~200k tokens of corpus) plus prompts and output, costing roughly 1-2 USD at Opus rates. The single-model approach also risks missing cross-references between files that fall outside the active attention window, which is exactly what happened with the onboarding guide reference the verifier caught.
The actual savings depend heavily on the ratio of scannable grunt work to judgment-required decisions. In this case, most of the work was scanning (workers did it cheaply), and the leader only touched deduplication and fix application. On a task with less parallelizable scanning, the savings would be smaller.
How to trigger it
Drop SKILL.md into .claude/skills/flavor-neo/ (or wherever your agent reads skills from). Then say:
flavor-neo: audit all markdown files in docs/ for contradictions against the codebaseThe leader (your strong model) reads the skill, plans the lanes, dispatches workers, collates, and sends to the verifier. You don't manually configure the loop; the skill protocol handles the structure. You provide the scope and the goal contract.
If you only have access to one model family (say, only Claude), the skill specifies that the verifier should be a different model family than the workers. In practice, if cross-family access is not available, running the verifier as a separate agent with completely fresh context (no shared conversation history) still catches many issues that self-review misses, though correlated blind spots remain a risk. The key constraint is that the verifier never sees the workers' reasoning.
Where this breaks
The happy path above is real, but so are these failure modes:
Workers producing garbage. Cheap models sometimes hallucinate contradictions that don't exist, especially when scanning code they don't fully understand. The collation step catches most of these (the leader is a strong model and can distinguish real findings from noise), but if all three workers hallucinate the same non-issue, it passes through. Mitigation: the verifier reads the actual files, not the worker reports, so fabricated findings get caught at the gate.
Verifier leniency. A verifier that rubber-stamps fixes is worse than no verifier at all, because it creates false confidence. This happens most often when the verifier's prompt is too loose or when the goal contract is vague. Mitigation: the goal contract must specify concrete, checkable criteria. "Improve the docs" is not a contract. "Every service name in docs/ matches the directory name in src/" is.
Lanes that aren't independent. If Worker A's lane overlaps with Worker B's, the collator has to reconcile conflicting findings about the same file. This is coordination overhead that the pattern is supposed to avoid. Mitigation: split lanes by deliverable, not by activity, and verify that file lists don't overlap before dispatching.
The strong model failing at collation. The leader is responsible for deduplication, prioritization, and fix quality. If the leader makes a bad fix, the verifier should catch it, but if both the leader and verifier miss the same thing, it ships broken. This is the residual risk the pattern cannot eliminate. It reduces the probability but does not reach zero.
The commit trail
Every Flavor Neo run produces a commit with a structured message:
flavor-neo batch 1: resolve 18 contradictions (C-01–C-18), GPT-5.4 verified
3 worker lanes (Claude Haiku: arch, dates, docs) + collator (Opus 4.6) + verifier (GPT-5.4).
Round 1: 16 fixes passed, verifier caught 2 + 1 new → REVISE.
Round 2: all 3 delta fixes passed → PASS.
Resolved:
- C-01: docs/architecture.md — updated service name from old-api to gateway-v2
- C-02: README.md — corrected last-updated date from 2025-11 to 2026-06
...
Still open: C-19 (LOW) — comment in test/helpers.ts references removed fixtureThis matters for auditability. Six months from now, someone looking at git log can see exactly what was checked, by which models, how many rounds it took, and what was left open.
What this actually buys you
Token cost drops significantly because only the leader (the expensive model) touches every decision; the bulk of scanning happens on models that cost 5x less per token. The exact savings depend on how much of the task is parallelizable scanning vs. judgment. In the documentation audit above, the ratio was roughly 10:1 in favor of scanning, so the Flavor Neo run cost ~0.20 USD versus ~1-2 USD for a single Opus pass. On a task that is mostly judgment, the savings would be smaller.
Correctness goes up because nothing ships on the implementer's say-so. An independent, fresh-context check gates every result. Cross-model verification catches correlated blind spots that same-model self-review misses.
It scales to long, unattended work because the brake and the goal contract mean it can run without you watching, and it fails loudly instead of quietly drifting.
The audit trail is automatic. Every run documents what was found, what was fixed, what was verified, and what remains open.
When not to use it
Under 3 files. Just do it yourself. The coordination overhead exceeds the benefit.
Code changes with test suites. Tests are the verifier. You don't need a second verification loop when
npm testalready gates correctness.Simple single-file edits. A leader-only pass is fine. Don't bring the full loop to fix a typo.
The ideas behind it
None of this is exotic. It's five well-known principles applied to agents instead of teams and machines:
Brooks's Law: adding people to a late project makes it later, because communication overhead grows faster than throughput. The same principle applies here: more workers means more coordination, so cap them at 2-4 where diminishing returns set in.
NASA WBS 100% rule: child scopes must sum to exactly the parent, no gaps, no overlap. That's Rule 3.
Verification ≠ validation (systems engineering): verification asks "did we build it right?" (does the output meet the spec); validation asks "did we build the right thing?" (does it meet the user's actual need). In this loop, unit tests handle basic verification. The independent verifier checking against the goal contract adds a second layer of verification from a fresh perspective, catching specification-level errors the implementer's own tests miss. That's Rule 4.
Donella Meadows on balancing feedback: in Thinking in Systems, Meadows shows that feedback loops with delays and insufficient damping overshoot or oscillate. The hard brake (≤3 rounds) is the damping mechanism. Without it, the revise loop can thrash indefinitely between competing fixes. That's Rule 5.
The "Fable as leader" pattern (Machina / @EXM7777): use the strongest available model as orchestrator, not as laborer. The insight that leadership and labor want different cost profiles.
The skill is open source, a single markdown file you drop into .claude/skills/: