How I Run Long-Running Agents at an Insurance Company
Durable orchestration, checkpointing, and human-in-the-loop in production

Insurance companies run on processes that take days, not milliseconds. A claim gets filed. It sits in a queue. An adjuster reviews it. Someone requests more documents. A supervisor signs off. Weeks pass. This is the reality I work in — and it turns out, it's a perfect forcing function for building robust long-running AI agents.
Over the past year, I've shipped several agents into production at the insurance company where I work. These aren't chatbots. They're systems that autonomously process documents, query internal databases, draft correspondence, escalate edge cases, and hand off to humans — across hours, sometimes days. Here's what I learned.
Why "Long-Running" Is a Different Problem
Most agent tutorials show you something that completes in under 30 seconds. Prompt in, tool calls, response out. Clean.
Real enterprise workflows don't look like that. My agents need to:
Wait for a human to upload a document before continuing
Pause mid-task because a downstream API is throttled
Resume after a weekend without losing context
Survive infrastructure restarts, deployments, and the occasional Kubernetes eviction
The moment your agent spans more than one process lifetime, you've entered a different design space. You need persistent state, explicit checkpointing, and failure recovery — not just a retry decorator.
Architecture: The Three Layers
After a lot of iteration, I landed on a three-layer architecture.
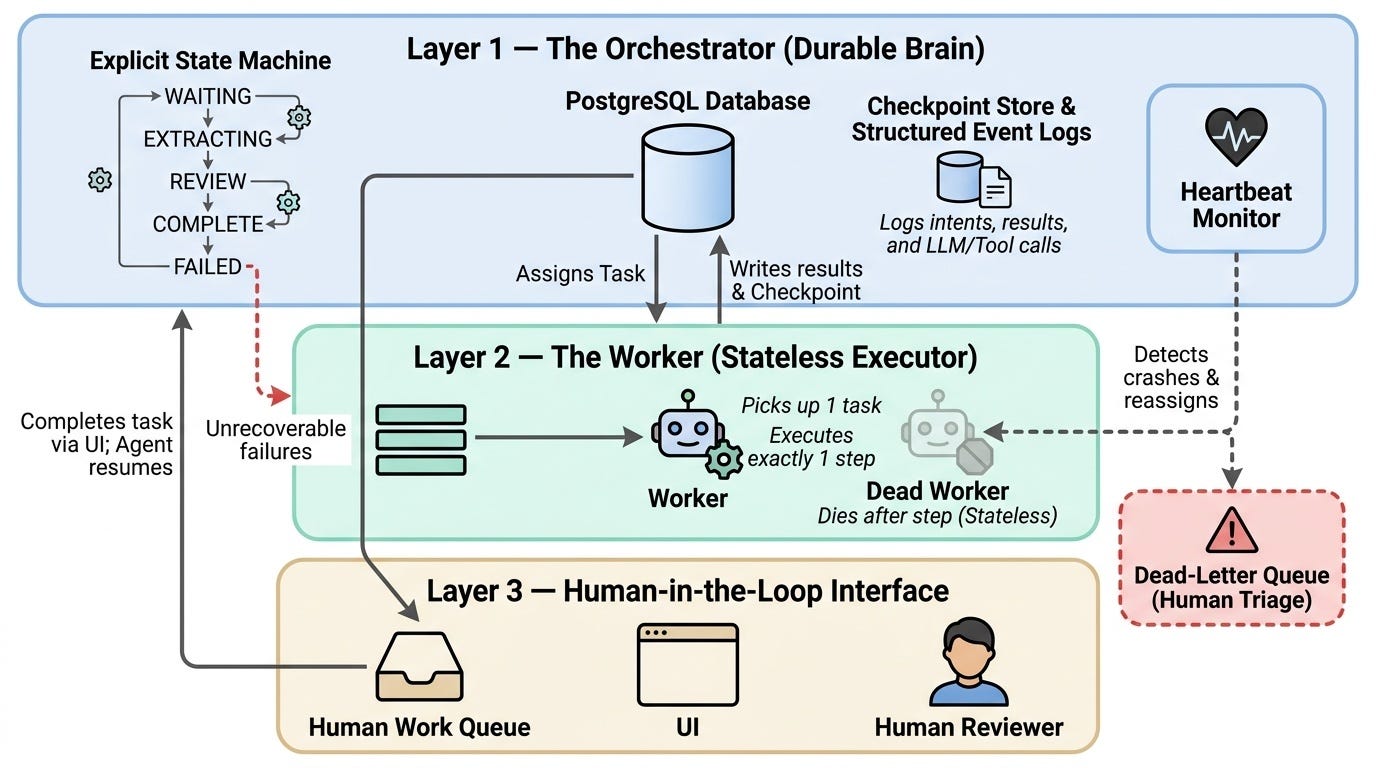
Layer 1: The Orchestrator
This is the durable brain. It knows what the agent is supposed to accomplish, what steps have been completed, and what comes next. It lives in the database, not in memory. Every time the agent advances a step, the orchestrator writes a checkpoint before doing anything else.
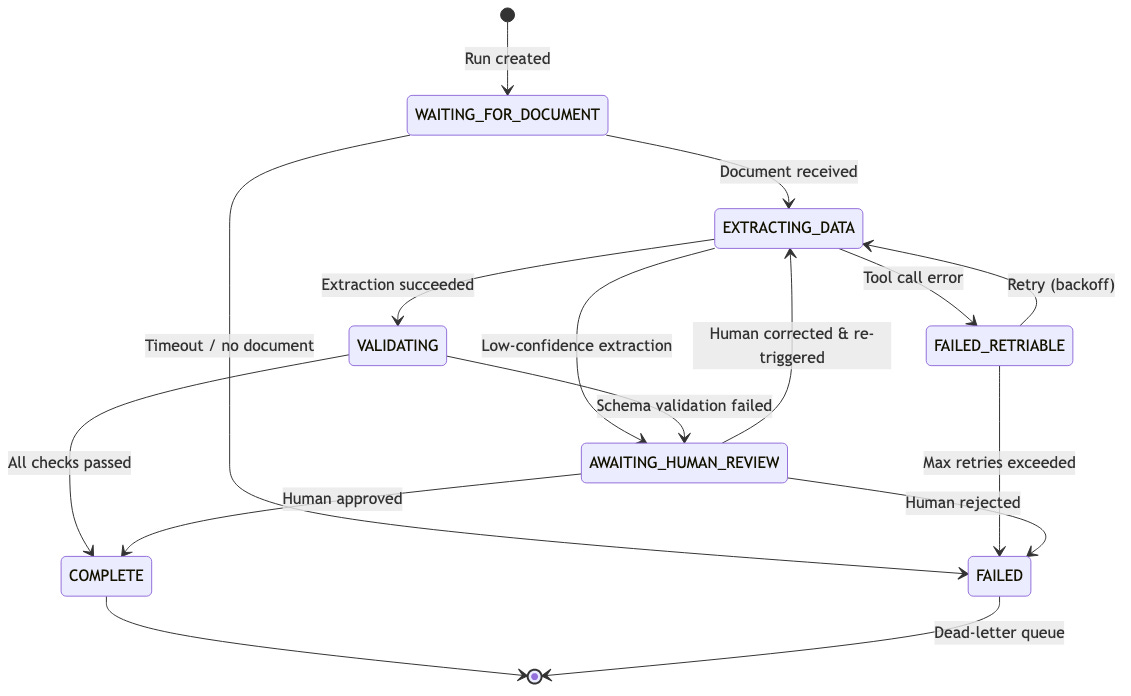
I model each agent run as a state machine. States are explicit: WAITING_FOR_DOCUMENT, EXTRACTING_DATA, AWAITING_HUMAN_REVIEW, COMPLETE, FAILED. Transitions are logged. You can reconstruct exactly where any agent run is — and was — at any point.
Layer 2: The Worker
Workers are stateless. They pick up a task from a queue, execute one step of the state machine, write results back to the orchestrator, and die. If a worker crashes mid-step, the orchestrator detects it via heartbeat timeout and reassigns the task. No task is lost because no task lives only in the worker's memory.
This is the biggest mindset shift from building "chatbots": treat every agent step as a unit of work that can fail and be retried independently.
Layer 3: The Human-in-the-Loop Interface
Some steps require a human. I don't fight this — I model it explicitly. When the agent reaches a step that needs human input, it writes a task to a work queue and suspends itself. A human completes the task (via a simple UI). The agent is notified and resumes.
This means agents can be "paused" for days waiting on a human without holding any compute. The orchestrator just has a row in the database marked WAITING_FOR_HUMAN.
Checkpointing: The Thing That Actually Saves You
I checkpoint aggressively. Before every tool call. Before every LLM call. After every meaningful piece of work.
Here's the pattern I follow:
Write intent before acting. Before calling an external API, write "I am about to call X with these parameters" to the checkpoint store. If the process crashes, you know what was about to happen.
Write result after completing. After the call succeeds, update the checkpoint to "X returned Y." Now recovery is: did we complete this step? If yes, skip it. If no, re-execute.
Make tool calls idempotent. This isn't always possible, but where it is, do it. Generate a UUID per intent, pass it as an idempotency key to external APIs, and you can safely retry without duplicating effects.
The checkpoint store is just a Postgres table. Nothing exotic. Each row has: run_id, step_name, status, input_hash, output, created_at. The agent loads its checkpoint on startup and skips any steps already marked complete.
Observability: What I Wish I'd Built Earlier
When an agent run fails at step 7 of 12, three days into its execution, you need to be able to answer: What did it do? What did it see? Why did it make that decision?
I now instrument every agent run with:
Structured event logs: Every LLM call, every tool invocation, every state transition. Logged as structured JSON with
run_id,step,timestamp,input,output,latency_ms.Token usage tracking: LLM costs compound fast when you have hundreds of parallel agent runs. I log input and output tokens per call and alert when a run exceeds 2× the expected token budget.
A trace viewer: I built a simple internal UI that lets me pull up any agent run by ID and see its full timeline. This was a weekend project that has saved me countless hours of log-diving.
Anomaly alerts: If a run has been in
WAITING_FOR_HUMANfor more than 48 hours, we alert. If a run exceeds its expected duration by 3×, we alert. These are just cron jobs querying the orchestrator table.
The key insight: treat your agent runs like distributed transactions. The tooling exists for observing distributed systems — adapt it.
Handling Failures Gracefully
Agents fail. LLMs hallucinate. APIs time out. Documents are malformed. I've accepted this and designed for it.
Retry with backoff on transient failures. Network errors, rate limits, and temporary API outages are transient. I retry these with exponential backoff, up to a maximum. After max retries, the step fails and the run enters FAILED_RETRIABLE state.
Escalate on semantic failures. If the LLM returns something structurally valid but semantically wrong (extracted a date that doesn't exist, classified a document into the wrong category), I don't silently swallow it. I escalate to human review. The agent writes a note explaining what it saw and why it's uncertain, and a human resolves it.
Dead-letter runs for catastrophic failures. If a run hits an unrecoverable error, it goes to a dead-letter queue. A human triages it. We track dead-letter rate as a KPI. If it spikes, something is systematically wrong and we investigate immediately.
Never let a run disappear silently. This sounds obvious but it's easy to miss. An agent that crashes without updating its status looks identical to an agent that's still running. I use heartbeats: every worker pings the orchestrator every 30 seconds. If a heartbeat is missed for 2 minutes, the run is marked as SUSPECTED_DEAD and reassigned.
Lessons From Production
Lesson 1: The context window is not your memory. Early on, I passed the entire history of a run into every LLM call. Costs exploded. Latency ballooned. Now I summarize completed steps into a compact "run summary" and only pass recent context in full. The agent doesn't need to re-read everything it's done — just know what it's already accomplished.
Lesson 2: Humans are part of the system. I used to think of human-in-the-loop as a failure mode — something to minimize. Now I treat it as a first-class system component. Some decisions should go to humans. The agent's job is to make those handoffs clean and well-documented, not to eliminate them.
Lesson 3: Idempotency is load-bearing. Every time I skipped making a tool idempotent because "it's unlikely to be retried," it got retried, and something bad happened. It's always worth the 10 extra minutes.
Lesson 4: Schema-validate every LLM output. Every LLM call in my agents returns structured output validated against a schema at runtime. If the schema check fails, the step fails — loudly, with a detailed error — rather than propagating garbage downstream.
Lesson 5: Separate the LLM from the decision. The LLM suggests. The orchestrator decides. I don't let LLM output directly trigger irreversible actions. There's always a thin validation and approval layer between "the model said X" and "the system did X."
The Payoff
Running agents in this environment is genuinely hard. The failure modes are subtle, the stakes are real (insurance decisions affect people's lives), and the organizational context is conservative by design.
But it's also deeply rewarding. The agents I've shipped process hundreds of cases a week that would otherwise queue for days. They catch document inconsistencies humans miss at 2am. They make the humans who do review cases faster and more confident because the boring legwork is already done.
The patterns here — durable orchestration, aggressive checkpointing, explicit human handoff, observable runs — aren't specific to insurance. They apply anywhere agents need to survive contact with the real world.
Build for failure from day one. Your future self will thank you.