How to Build a Killer LLM Studio in 2026
A system design deep-dive: six services, one gateway, and the engineering decisions that actually matter

Most teams building on top of LLMs in 2026 are doing one of two things: calling an API and calling it a day, or drowning in MLOps complexity trying to replicate what hyperscalers do.
Neither works if you actually want to own your model's behaviour.
This post is a system design walkthrough of an LLM Studio — the software infrastructure that lets a small team run the full model-improvement loop end to end. Think of it like a HelloInterview deep dive, but the system being designed is your own fine-tuning platform.
What Problem Are We Actually Solving?
The core loop of model ownership looks like this: you have a task, you have data, you want a model that gets better at that task over time. The challenge isn't the ML math — libraries handle that. The challenge is the software infrastructure around it.
You need to:
Ingest and version training data (including synthetically generated data)
Run fine-tuning jobs without blocking everything else
Serve the resulting models without redeploying when new checkpoints land
Evaluate models against each other without writing one-off scripts
Let non-ML engineers trigger experiments through a UI
A notebook can do one of these. A studio does all of them, reliably, repeatedly.
High-Level Architecture
The studio is six loosely coupled services. Each has a single responsibility, its own database schema, and communicates over HTTP.
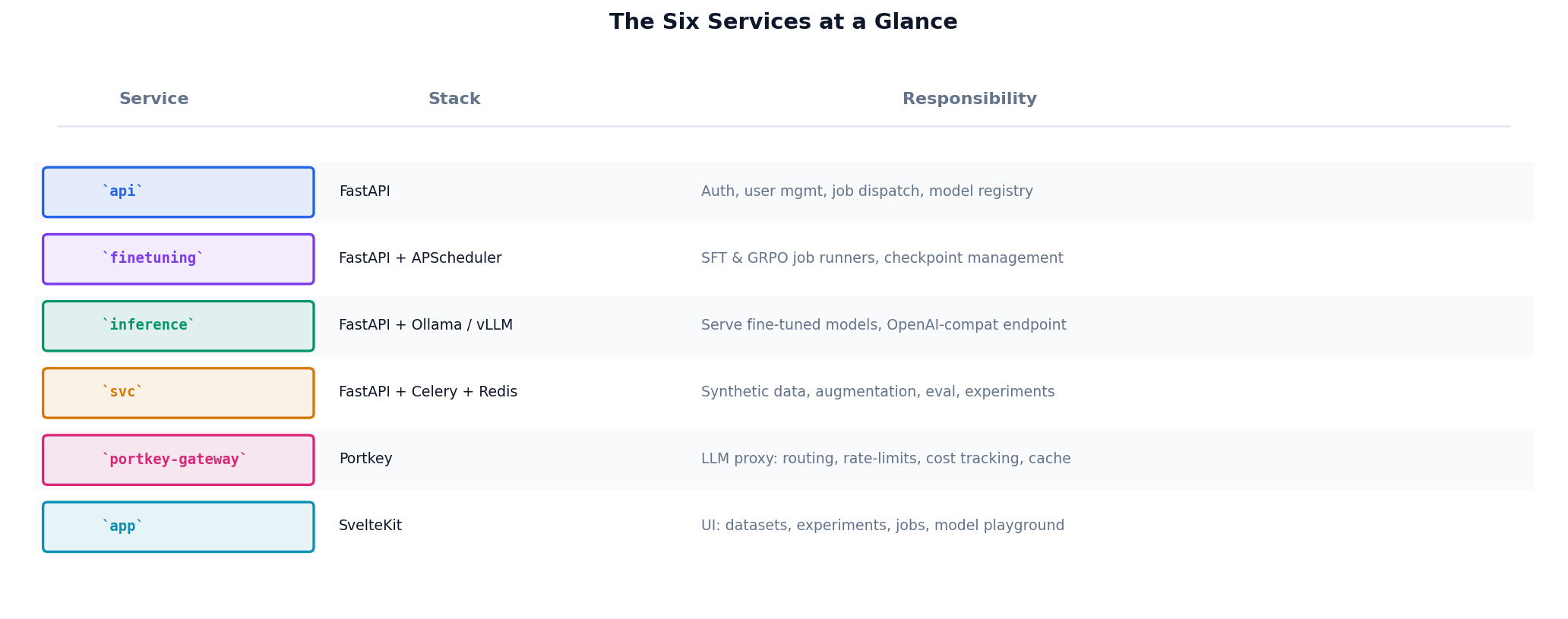
The two most important separations:
Finetuning and inference have different lifecycles. Training is GPU-hungry, bursty, and failure-tolerant — if a job crashes, retry it. Inference is always-on and latency-sensitive — if it crashes, users notice. Coupling them in one process means a bad training job can kill your serving layer.
The data service is its own thing. Synthetic data generation is slow (minutes per batch), LLM-heavy, and produces intermediate artefacts that need versioning. Baking it into the API would turn every data request into a blocking call.
Deep Dive: The Finetuning Service
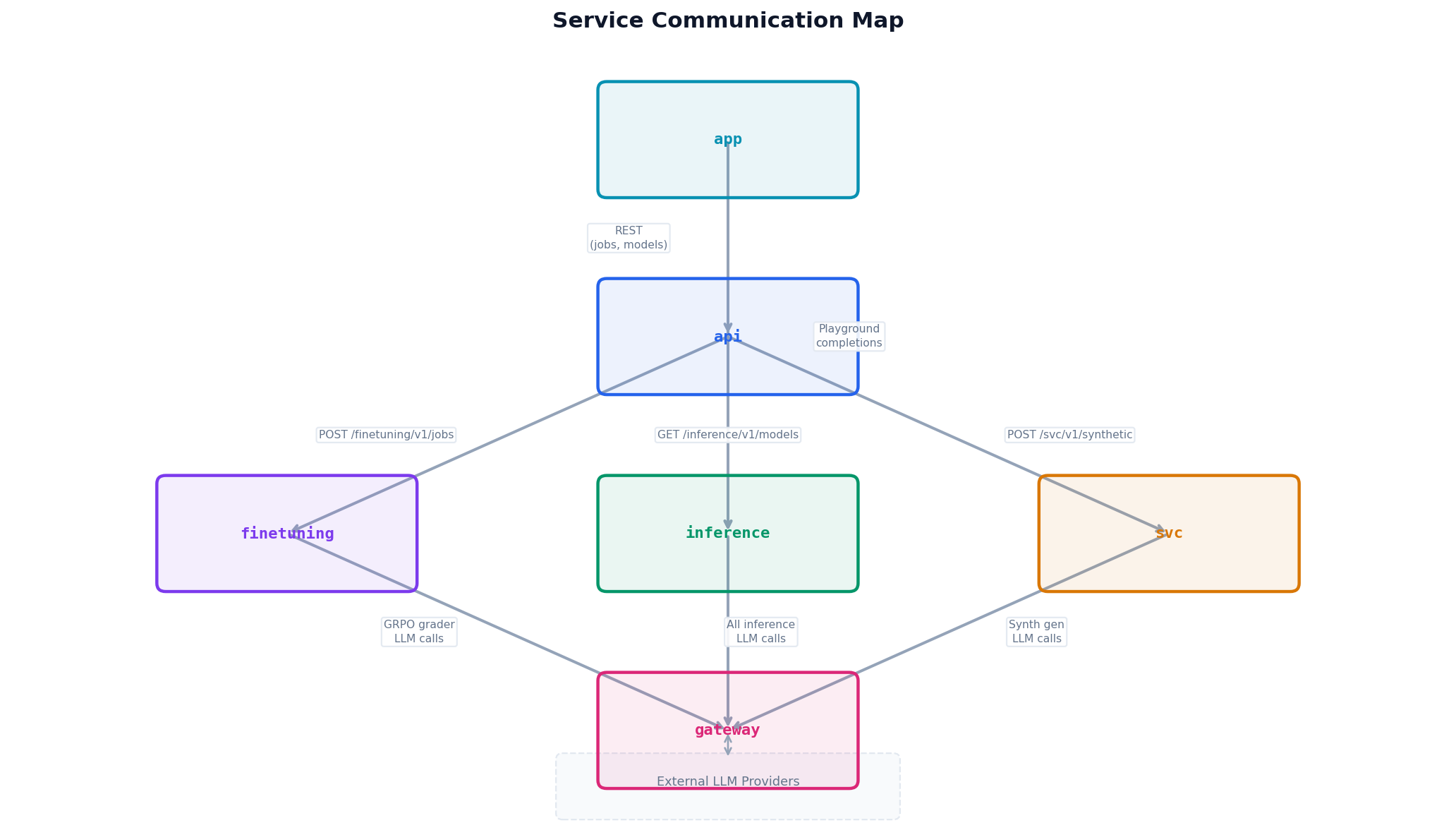
This is the most complex service. Its job is to take a submitted training request and reliably produce a fine-tuned model checkpoint.
Job Scheduling
The service uses APScheduler with a background scheduler running three recurring jobs:
scheduler.add_job(finetuning_scheduler.run_fine_tuning_jobs, "interval", seconds=N)
scheduler.add_job(finetuning_scheduler.check_running_jobs, "interval", seconds=N)
scheduler.add_job(finetuning_scheduler.check_jobs_waiting_for_checkpointing, "interval", seconds=N)Why a polling scheduler instead of a task queue? Because fine-tuning jobs are long-running (minutes to hours) and stateful. Celery is designed for short tasks. APScheduler lets the service own the full job lifecycle — queuing, running, checkpointing, failure — without fighting a task framework's assumptions.
The Training Runners
Two runners live inside the finetuning service: one for SFT (Supervised Fine-Tuning) and one for GRPO (the reinforcement learning variant). They're separate processes, not just functions — the runner is launched as a subprocess with explicit hyperparameter flags. This means:
A runner crash doesn't take down the service
You can run multiple jobs in parallel on separate GPUs
Runner code can be updated without restarting the scheduler
Checkpoints get written to a shared filesystem path and the service marks the job as CHECKPOINTING before promoting the adapter to the model registry.
Deep Dive: The Inference Service
The inference service exposes an OpenAI-compatible chat completions endpoint. The model underneath can be Ollama (local dev) or vLLM (production), but the contract to callers doesn't change.
POST /inference/v1/chat/completions
{ "model": "my-finetuned-adapter-v3", "messages": [...] }Why Ollama Locally, vLLM in Prod?
Ollama is trivially easy to set up on a laptop — ollama pull llama3 and you're serving. But Ollama's throughput is single-request, which is fine for development and the model playground, but not for evaluation runs that fire 200 completions in parallel.
vLLM uses continuous batching — incoming requests share KV cache and GPU compute. For the GRPO training loop, which needs to generate 8 completions per prompt across thousands of prompts, vLLM is 5–10x faster. The service switches backends by environment variable; no code changes needed.
For burst production workloads, the same service can be pointed at a Modal-hosted endpoint — GPU spins up on demand, billing stops when idle.
Deep Dive: The Data Service (`svc`)
The data service handles everything that touches training data: ingestion, synthetic generation, augmentation, curation, and evaluation. It's the most Celery-heavy service in the stack.
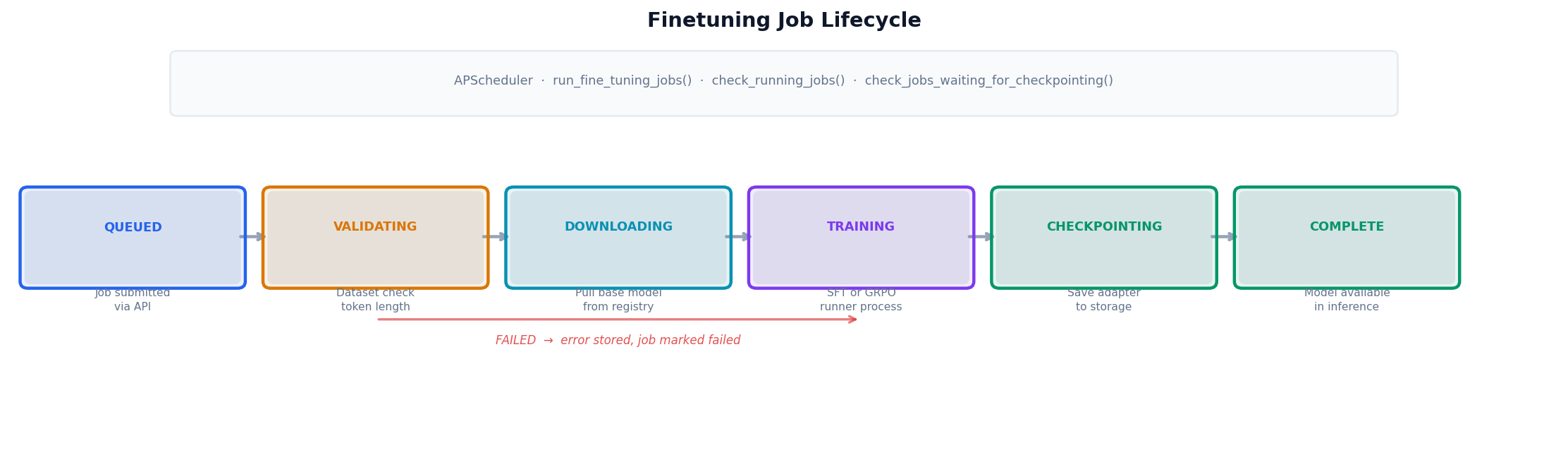
The Synthetic Data Pipeline
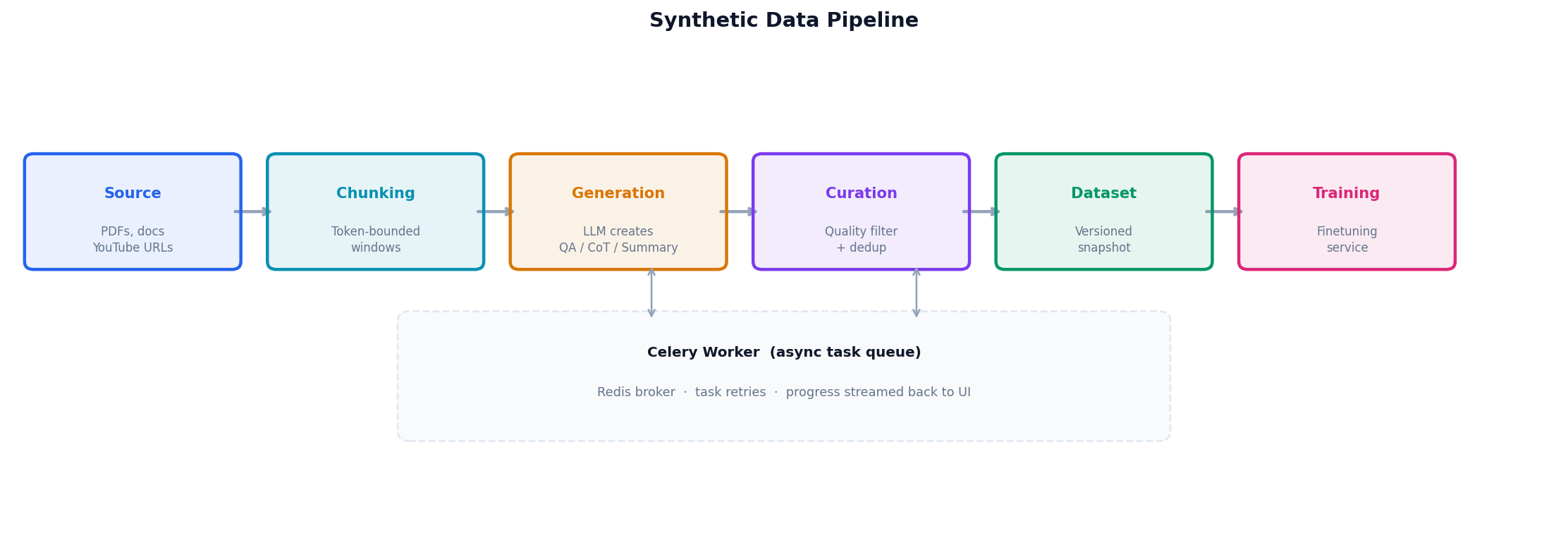
The pipeline is async by design. A generation request comes in via the API, gets dispatched to a Celery worker, and the frontend polls for progress. The worker:
Ingests source documents (PDFs, plain text, YouTube transcripts via the API)
Chunks the content into token-bounded windows
Calls the LLM gateway to generate pairs (QA, CoT, or summaries)
Streams completed pairs back to the dataset in real-time
Marks the task complete and updates the dataset snapshot
The three generation modes matter architecturally, not just academically:
QA pairs are cheap and fast to generate, good for instruction-following baselines
Chain of Thought pairs cost ~3x more tokens but produce dramatically better structured-output models — the model learns to reason before answering
Summaries are useful when your inference task involves compression, not extraction
Evaluation
The evaluation service can run multiple models against a snapshot in parallel and score them using either an LLM-as-judge rubric or a bring-your-own-evaluator endpoint. Results stream back per-datapoint, so you see the leaderboard filling in live rather than waiting for a batch job to complete.
Deep Dive: The Gateway
Every LLM call in the entire system — synthetic data generation, evaluation, GRPO reward scoring, the model playground — goes through a single gateway layer. This is not optional architecture astronautics. It pays for itself immediately.
What you get for free:
Cost visibility — which service is spending what, on which model
Routing — fall back from GPT-4o to Sonnet if one provider is down
Caching — identical prompts during eval runs don't get billed twice
Rate limit management — the gateway absorbs burst traffic so individual services don't need to implement retry logic
The gateway is a thin sidecar — one Docker container, no business logic. Portkey, LiteLLM, or a self-hosted proxy all work. The key is that it's a hard architectural boundary: no service calls an LLM provider directly.
Deep Dive: The API and Frontend
The api service is the single front door. It handles:
Auth — API key verification for all service-to-service calls
Job dispatch — accepts training requests and forwards them to the finetuning service
Model registry — tracks which checkpoints exist and their metadata
Dataset management — versions snapshots, stores split configurations
The frontend is SvelteKit. The key UI surfaces are: dataset view (upload, inspect, generate), experiment configurator (pick base model + hyperparameters), job monitor (live training logs), and the model playground (side-by-side completion comparison).
Local vs Production
Running locally and running in production are architecturally identical — same six services, same HTTP contracts. The only differences are the backing implementations:
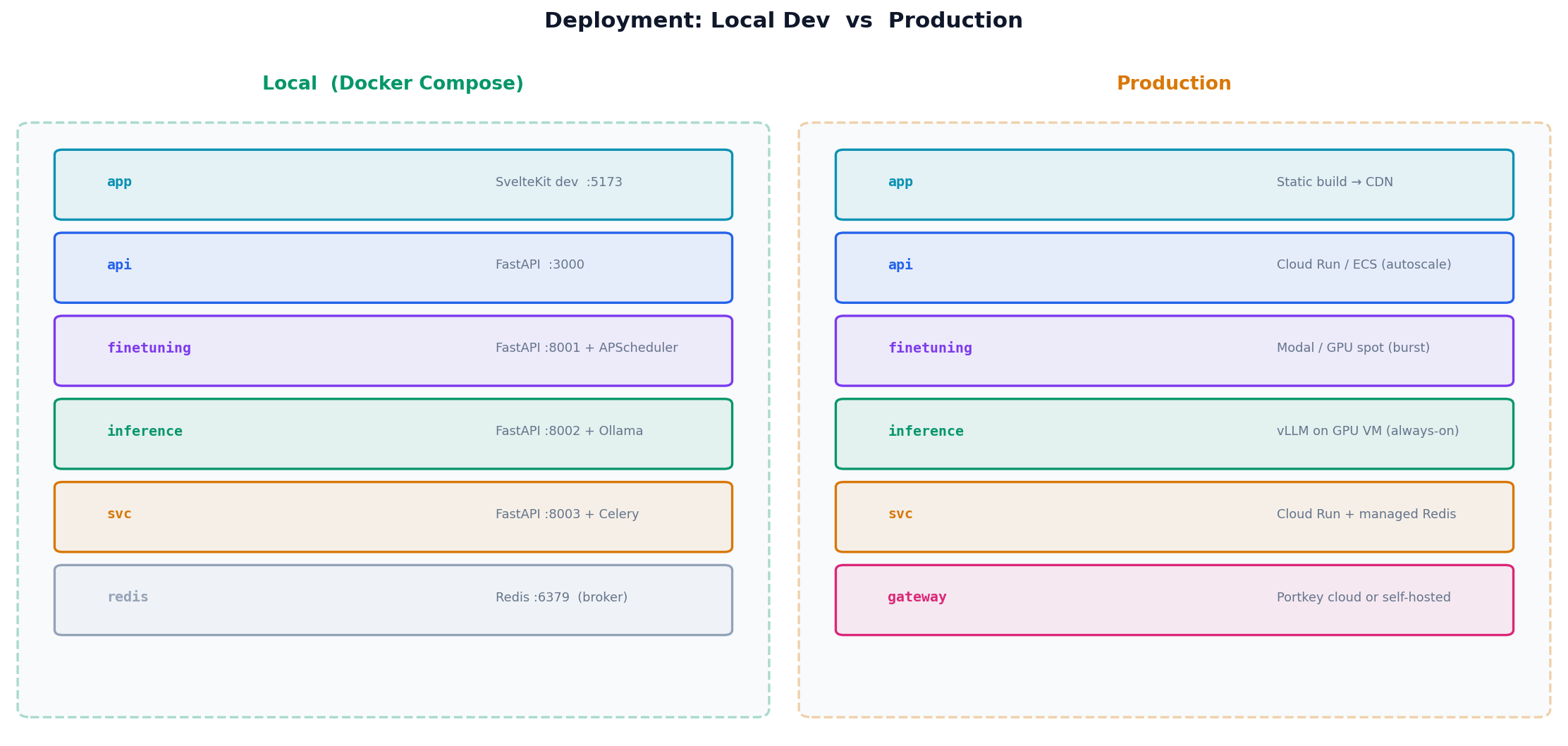
The local stack boots with a single docker compose up. Each service gets its own container, Redis runs as a sidecar, and Ollama handles inference. Switching to production means swapping environment variables — no code changes.
Key Design Decisions
Why not a monolith? A monolith works until you need to scale the finetuning service to GPU machines while keeping the API on cheap CPU containers. Service separation lets each component scale independently and fail independently.
Why polling for job state instead of webhooks? Training jobs run for minutes to hours. Webhook delivery has a real failure surface over that timeframe. The frontend polls /api/jobs/:id every few seconds — simple, robust, no webhook infrastructure needed.
Why Celery for data tasks but APScheduler for training jobs? Celery is optimised for many short tasks with a shared worker pool. Training jobs are one long task per GPU — APScheduler's interval-based polling and explicit state machine fits better.
Why OpenAI-compatible inference endpoints? Every evaluation library, every agent framework, every LLM client already speaks this protocol. Wrapping your fine-tuned model in a compatible endpoint means zero integration cost downstream.
What Breaks at Scale
A few things that look fine in development but become problems in production:
Shared filesystem for checkpoints. Locally, all services can read the same path. In production, you need an object store (S3, Azure Blob) as the checkpoint backend, with the finetuning and inference services both mounting it. This is a one-line config change if you design for it upfront.
Celery worker saturation. A single LLM call for synthetic data generation can take 10–30 seconds. If you have 10 concurrent generation tasks each firing 100 LLM calls, your worker pool fills up fast. Separate worker queues for fast tasks (evaluation) and slow tasks (generation) early.
No rate limiting on the evaluation service. Running evals against all models in your registry against a large dataset can fire thousands of LLM calls in minutes. The gateway handles rate limits, but the evaluation service should have a concurrency cap per eval job.
SGLang vs vLLM: Which One Goes in the Inference Service?
The studio's inference service is deliberately abstracted behind an environment variable. Locally it points at Ollama. In production, you pick an engine. And in 2026, that means choosing between vLLM and SGLang — two projects that started as competitors but have now specialised into different niches.
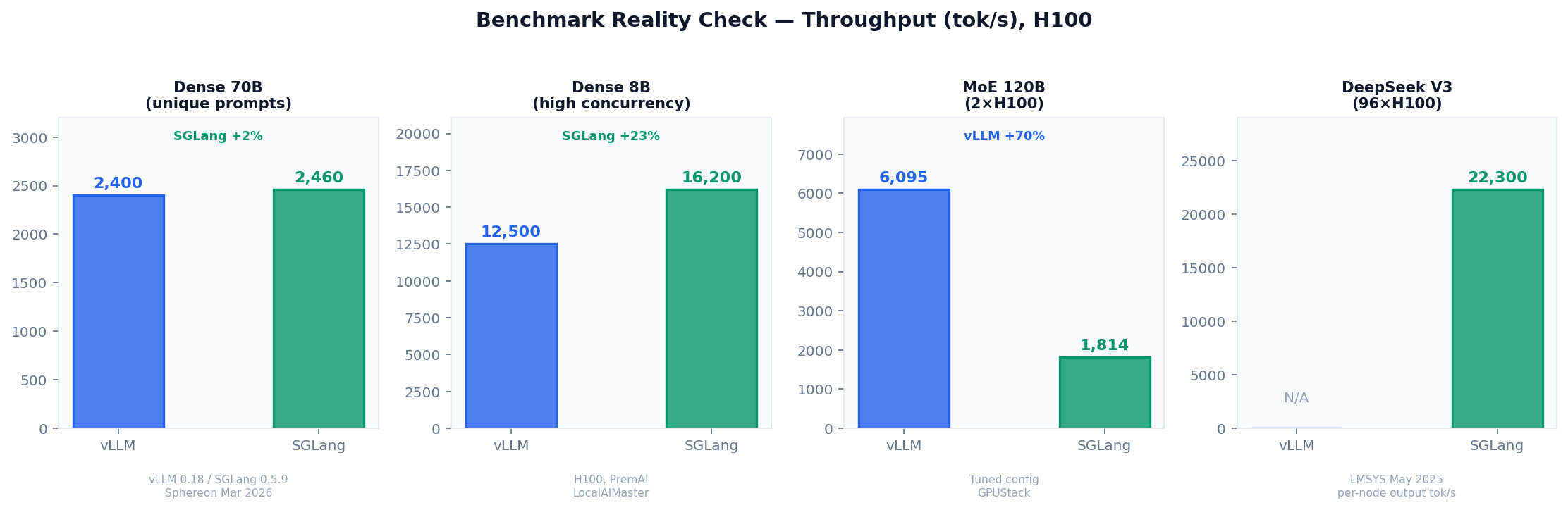
The 2024 narrative of "SGLang is 3× faster" no longer holds. vLLM's V1 rewrite (January 2025) pulled the two within 3–5% on dense 70B models at typical concurrency. But diverge from that workload profile and the gap opens sharply in one direction or the other.
The Core Architectural Difference
The engines diverge fundamentally on how they store KV cache.
vLLM uses PagedAttention — fixed-size physical blocks, hash-based per-block sharing, similar to OS memory paging. Predictable, well-understood, maps cleanly to most hardware.
SGLang uses RadixAttention — the entire live KV cache is a compressed prefix trie. New requests walk the tree from root; matched nodes mean their KV state is already on-GPU. When multiple requests share a system prompt, a retrieved document, or a conversation history, RadixAttention shares that prefix automatically across tenants with no configuration. The cache-aware router biases routing toward whichever worker holds the warmest matching prefix.
This isn't a marginal implementation detail. On agent loops, RAG pipelines, and multi-turn chat — anywhere prefixes repeat across requests — RadixAttention is the correct data structure and PagedAttention is the wrong one. The papers report up to 6.4× speedup on those workloads.
Where Each Wins

The MoE picture is stark. On GPT-OSS-120B with a tuned configuration, vLLM hit 6,095 tok/s versus SGLang's 1,814 — a 3.4× lead. DeepSeek V3/R1 runs in the other direction: SGLang's 96-H100 production deployment matches DeepSeek's own infrastructure throughput at roughly $0.20 per million output tokens, about one-fifth the cost of the public API. The DeepSeek GitHub repo officially recommends SGLang.
vLLM's durable advantage is breadth. It runs on NVIDIA, AMD, Google TPU, AWS Inferentia, Intel Gaudi, Apple Silicon, and IBM Z mainframes. SGLang covers most of those but TPU support lags. If you might multi-cloud, vLLM is the safer choice. It also covers ~200 model architectures — encoder-decoder, Mamba, Whisper, T5 — that SGLang doesn't support at all.
The Production Decision
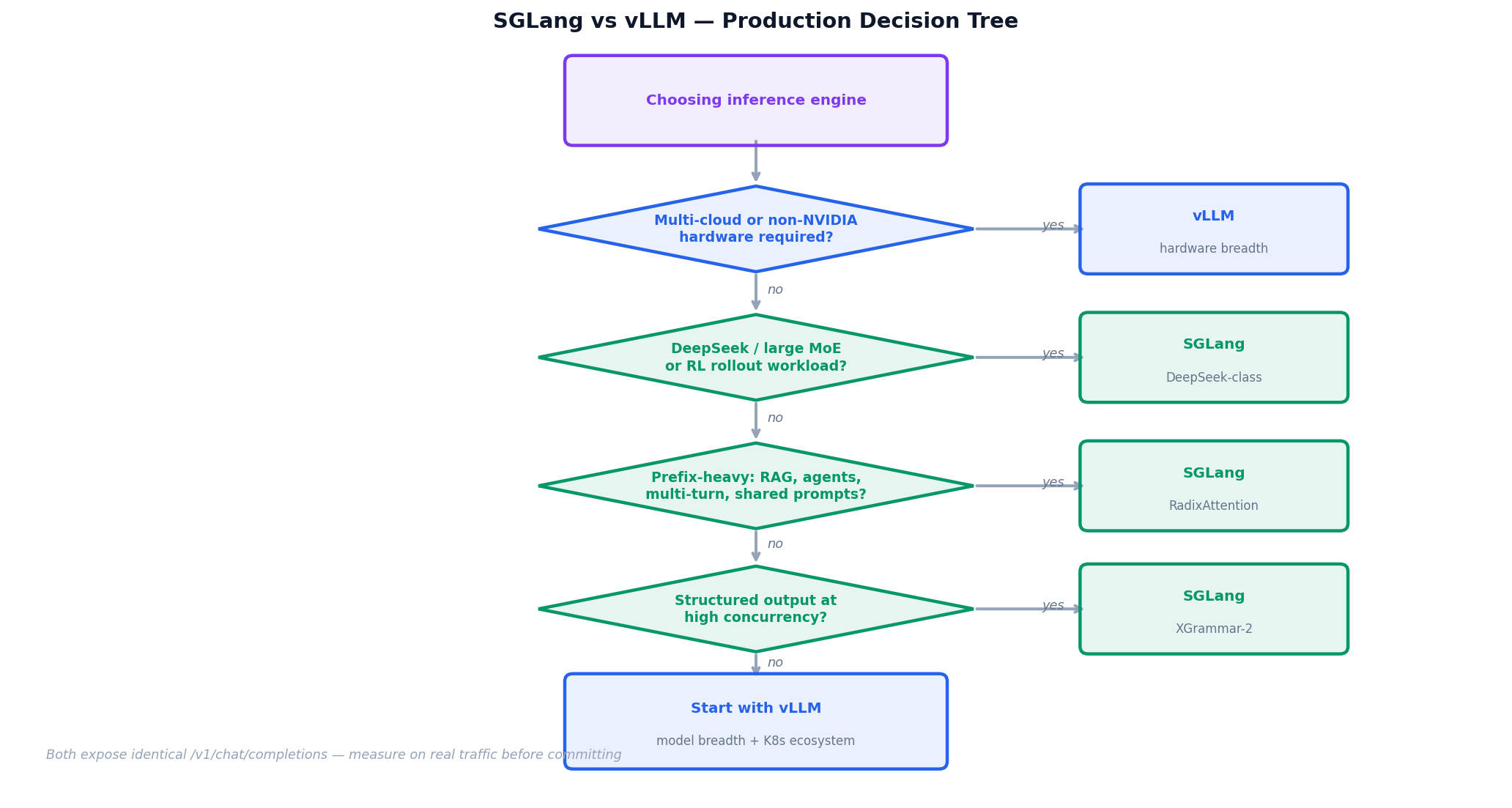
The default for a generalist team is start with vLLM. Then add SGLang as a second inference backend behind the gateway for the specific workloads where it wins: prefix-heavy pipelines, DeepSeek/MoE serving, structured output at scale, or RL training rollouts.
Both engines expose identical /v1/chat/completions semantics. The application-layer switching cost is genuinely near zero. Run both, route by workload type, measure on real traffic before committing to one.
The deeper shift is that in 2026 you're not picking an inference engine — you're picking a stack. Dynamo or llm-d on top, vLLM or SGLang underneath, with the gateway routing between them. The orchestration layer is increasingly engine-agnostic. What remains different — RadixAttention's tree, vLLM's hardware breadth, SGLang's DeepSeek depth — is exactly what makes the choice still matter.
The architecture is deliberately boring. Six services, HTTP, Postgres, Redis, one LLM gateway. The interesting engineering is in the details: the job state machine, the streaming data pipeline, the dual-backend inference layer. Those are where the real decisions live.
If you're building something like this or have questions about any of the design choices, I'd love to hear from you.