Log-Centric Agent Architecture
How event logs, deterministic projections, and replayable state change the way advanced agents are built

This tutorial is aimed at advanced readers who want to design agents around an append-only event log, deterministic projections, and replayable state instead of a chat loop with bolted-on memory and observability.
The Problem With Conventional Agent Frameworks
Most agent frameworks are LLM-first: the conversation loop is the core, tools are attached to it, rules layer on top, and logging is bolted on at the end for observability. State is persisted as retrievable "memory."
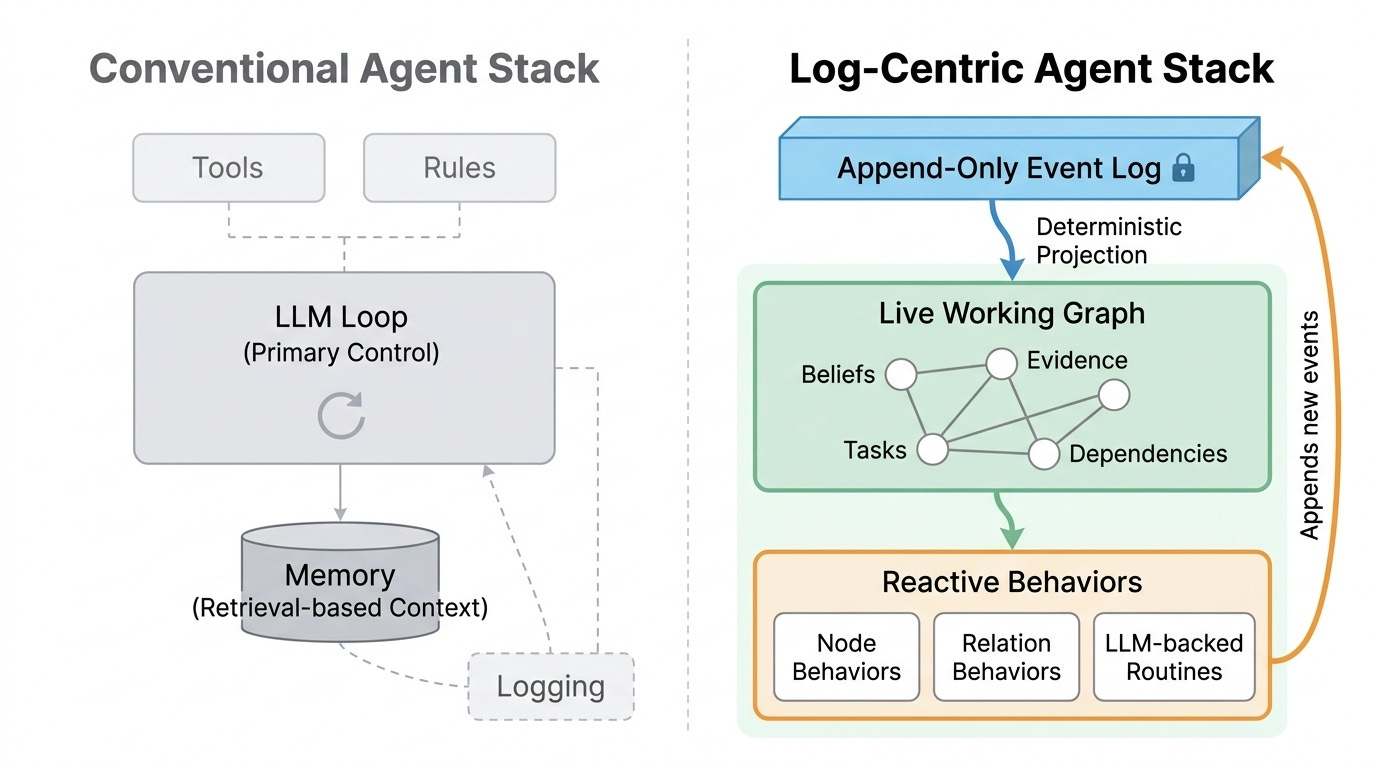
Figure 1. Conventional LLM-centric stacks treat logging as a secondary concern. In a log-centric design, the append-only event log becomes the source of truth, the working graph is derived from it, and the LLM is just one behavior among many.
Consequences of this design:
State is opaque: working memory lives in conversation context, not a queryable store.
Replaying a run is hard: there is no source of truth; logs are side-effects, not the primary record.
Forking is expensive: you must re-run from scratch because there is no checkpoint mechanism.
Coordination between agents is explicit: agents pass messages directly instead of reacting to a shared world state.
Observability is retroactive: tracing gets added after bugs appear.
The Core Inversion: Log-First Architecture
The core move is to invert the stack. Make the append-only event log the source of truth. Everything else — the working graph, the agent's beliefs, and task state — becomes a deterministic projection of that log.
The architecture shift is simple but profound: instead of treating the LLM loop as the runtime and storage as a helper, the event log becomes the runtime backbone. The live graph is derived from that log, and behaviors operate against the graph rather than owning the whole system.
The log is not observability. The log IS the agent.
A Concrete Runtime Shape
To make the idea concrete, think in terms of a runtime with three layers: authoritative events, projected graph state, and reactive behaviors.
Three-Layer Model
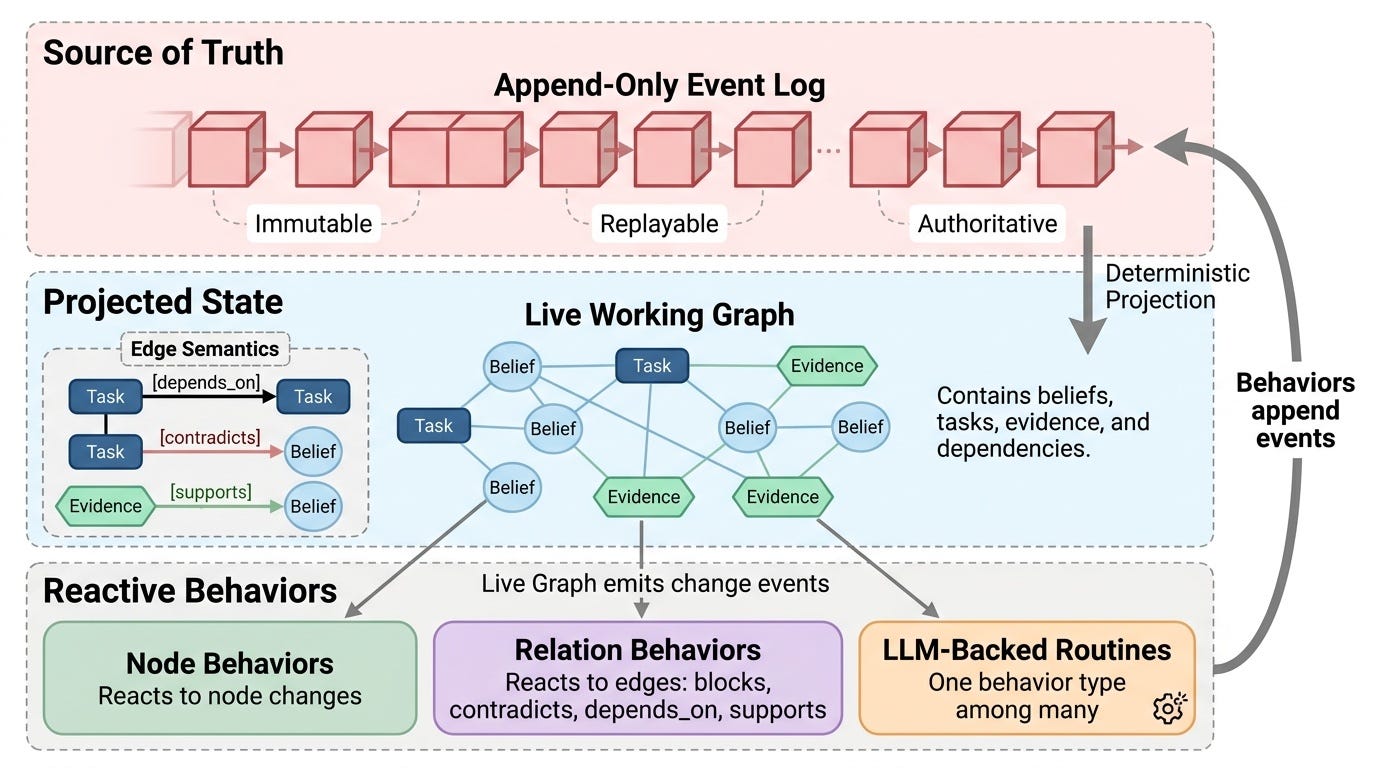
Figure 2. A three-layer runtime separates source-of-truth events, projected state, and reactive behaviors. Relation behaviors are first-class, and every behavior writes back to the shared event log.
Relation Behaviors — Edges as First-Class Citizens
Traditional agent graphs put all logic in nodes. A stronger design puts semantic logic on edges:
A task can
depend_onanother taskA task or belief can
contradictan existing beliefEvidence can
supportor weaken a claimBlocking, dependency, and contradiction logic live in the relationship itself
When the contradicts relation fires, a behavior automatically triggers — no explicit coordination code needed.
What the Log Enables: Four Superpowers
Deterministic Replay
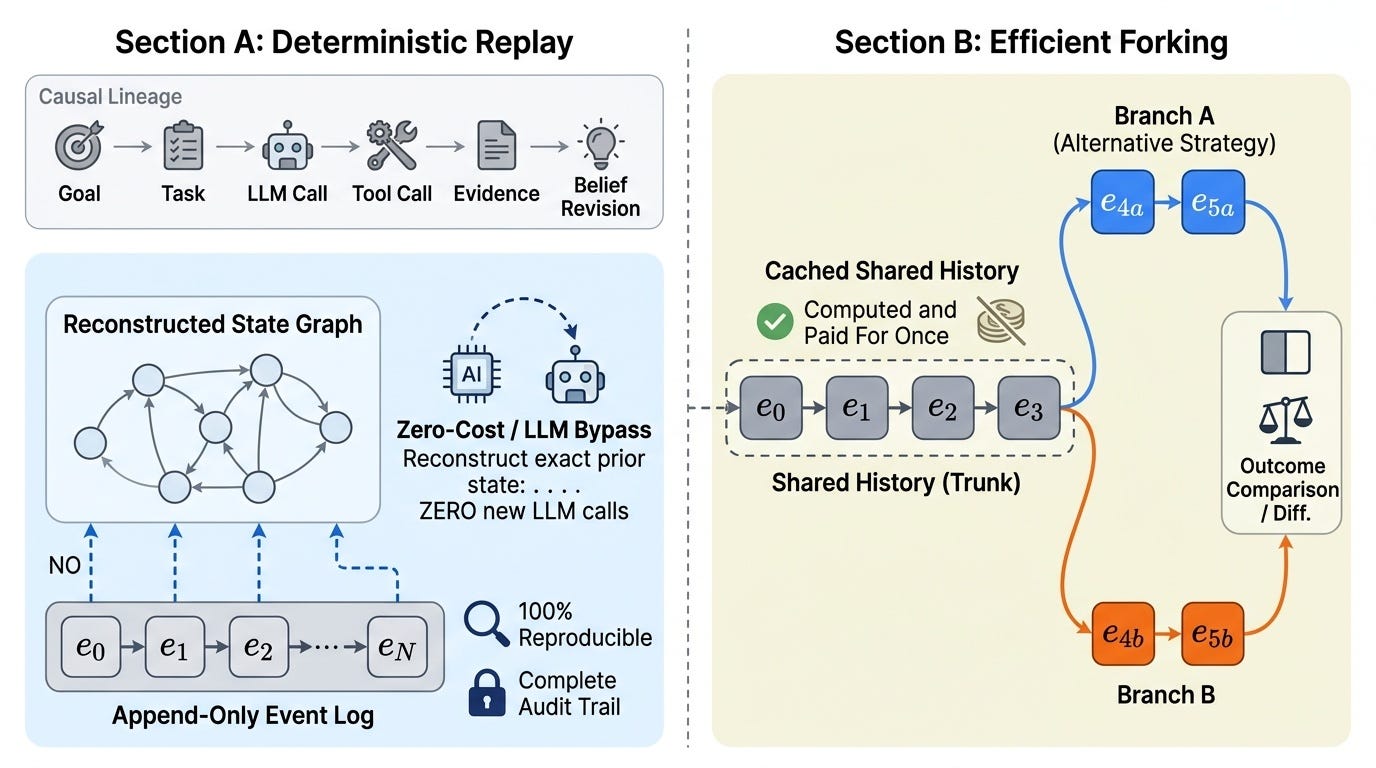
Figure 3. Once execution history is stored as events, replay becomes deterministic and branch exploration becomes cheap: reuse the shared prefix, pay only for divergent work, and compare outcomes directly.
Any run can be reconstructed exactly from its log. This means:
Full audit trail from goal to individual model call
Debugging without re-running expensive LLM calls
Compliance/reproducibility for regulated domains
Efficient Forking
Fork at any historical event. The shared prefix replays from cache — no redundant LLM calls for the common history. Branch, diff, compare outputs.
Complete Causal Lineage
Every event knows what caused it:
Goal: "Analyze market"
└─ spawned Task: "Research competitors"
└─ LLM call: "List top 5 competitors"
└─ Tool call: web_search("competitor analysis 2026")
└─ Evidence node: search result
└─ Behavior: "contradicts" edge fired
└─ LLM call: "Revise belief about market stability"No more "why did the agent do that?" — the log has full provenance.
Implicit Coordination (No A2A Protocol Needed)
Agents coordinate by reacting to the graph, not by calling each other. No explicit A2A protocol. No DAG. No workflow engine.
Deep Dive — Runtime Design Details
The Event Schema
Every event in the log carries:
`id`:
id:** unique identifier.`type`:
type:** event category such astask.created,llm.response, ortool.called.`payload`:
payload:** event-specific data.`actor`:
actor:** which behavior emitted the event.`causality`:
causality:** the triggering event or events.`timestamp`:
timestamp:** wall-clock time of emission.
The causality chain is what makes full lineage possible — every event knows its parent.
Handling LLM Non-Determinism
The hardest problem in event-sourced agents is that LLMs are not pure functions. The practical answer is content-addressed caching keyed on a normalized hash of the request such as system message, model parameters, and output schema. On replay, a matching hash serves the cached response from the log instead of making a fresh API call.
Two replay modes:
Permissive — serves cached responses, allows new calls for edited prompts (default)
Strict — validates byte-for-byte reproducibility; flags the first offending event if anything diverges
Forking Economics
The cost savings from cached prefix replay are concrete:
200-step run, fork at step 150:
├─ Steps 0–149 → replay from cache → $0, ~0ms per step
└─ Steps 150–200 → execute normally → full cost
Without forking: pay 200 steps × N variants
With forking: pay 50 steps × N variants + 150 steps onceFork lineage is verified by literal shared event IDs — not a copy, the same events. The structural diff then shows exactly which graph objects, relations, and patches differ between branches.
The Determinism Contract
Behaviors must not:
Call
random()directly (use event-record entropy instead)Read wall-clock time directly (use event timestamp)
Generate fresh UUIDs (obtain from event records)
Perform I/O outside framework primitives
Depend on mutable global state
The runtime does not statically enforce this. Violations surface at replay as a divergence error pinned to the first mismatched event. For LLM calls, the contract applies to replay (via cache), not initial execution.
What a Real Run Looks Like
In a realistic agent workflow, the event stream gets large quickly. A run can look like this:
671 events
93 objects (3 companies, 24 questions, 25 claims, 3 memos)
76 relations
103 model calls
48 tool calls
0 lines of orchestration codeCoordination was entirely reactive — no explicit scheduling, no DAG, no workflow engine.
Lineage is the deliverable — every claim links back to its behavior, triggering event, and specific model request. The causal chain from goal to output is reconstructable from the log alone.
Comparison to Memory-Layer Approaches
Memory-layer systems treat memory as a derived layer atop the agent. A log-centric design inverts that relationship: the log is primary, and memory in the form of a graph is a projection of it. That means you can reconstruct any past memory state, not just the current one.
Known Limitations
This architecture still has real limitations:
Reactive cascade risk: behaviors can trigger loops, so runs need budgets such as event caps, cost limits, and recursion depth.
Log scaling: replay cost is linear, and the system does not yet have mature compaction or checkpointing for million-event runs.
Schema evolution: graph schema changes require migration tooling.
Side-effect replay: external writes and emails happen only on first run; only responses replay cleanly.
No empirical benchmarks: the contribution is architectural rather than a head-to-head performance comparison.
Where Akka Fits — Filling the Production Gap
If you want to take this architecture into production, Akka is one of the clearest reference points for the surrounding infrastructure. It gives you battle-tested event sourcing, clustering, sharding, projections, and recovery semantics without asking you to invent those mechanisms from scratch.
Conceptual Mapping
The easiest way to read the mapping is this: the agent runtime contributes the agent-native abstractions, while Akka contributes the production-grade event-sourcing primitives. The concepts line up surprisingly cleanly.
What Akka Brings That A Minimal Agent Runtime Doesn't Have Yet
Log scaling: Akka Persistence snapshots let you snapshot state every N events and replay only the tail.
Schema evolution: Akka Persistence event adapters can transform older event formats on read.
Distributed multi-agent coordination: Akka Cluster Sharding routes behaviors to stable nodes and keeps state alive across failures.
External side-effect deduplication: Akka's at-least-once delivery model pairs with idempotent receivers so tools do not get re-executed incorrectly on recovery.
Backpressure in reactive cascades: Akka Streams gives you typed, backpressured pipelines so behaviors cannot flood one another.
Observability and metrics: Akka Telemetry provides message-rate, mailbox, and journal-latency visibility out of the box.
How a Production Log-Centric Agent Would Look With Akka
At production scale, you would expect persistent behavior actors writing to an event journal, projections building graph views from that journal, snapshots reducing replay cost, and a dedicated layer wrapping LLM calls as event-producing behaviors.
The Shared Philosophical DNA
Both this style of agent runtime and Akka are grounded in the same insight that the distributed systems community learned in the 2010s:
Mutable shared state is the enemy. Immutable events are the foundation.
Akka's EventSourcedBehavior (in Akka Typed) is nearly a direct implementation of a behavior attached to a projected log:
// Akka EventSourcedBehavior ≈ log-projected behavior
EventSourcedBehavior[Command, Event, State](
persistenceId = PersistenceId("agent", agentId),
emptyState = AgentState.empty,
commandHandler = (state, cmd) => Effect.persist(toEvent(cmd)),
eventHandler = (state, evt) => state.applyEvent(evt) // deterministic projection
)The difference is scope. Akka is a general distributed computing toolkit. An LLM-native runtime adds content-addressed LLM caching, a causality-aware event schema, fork-and-diff workflows, and graph projections typed around agent concepts such as beliefs, tasks, evidence, and relations.
When to Use Each
The practical split is straightforward:
Use a purpose-built log-centric agent runtime when you want the architecture directly, fast iteration, and agent-native concepts out of the box.
Use Akka when you already live in the JVM world and need battle-tested event sourcing, clustering, sharding, snapshots, and durable distributed runtime behavior.
Use a hybrid approach when you want the causal and replay model of a log-centric agent runtime but need the surrounding production infrastructure that mature event-sourcing stacks already solved.
Log-Centric vs Conventional — Side-by-Side
The core difference is not UI, prompt style, or framework ergonomics. It is where truth lives and what you can do once that truth is durable.
Source of truth: conventional systems rely on LLM conversation context; log-centric systems rely on an append-only event log.
State: conventional state is opaque and in-context; log-centric state is explicit and queryable through the graph.
Replay: conventional systems re-run from scratch; log-centric systems replay deterministically from the log.
Forking: conventional branching is expensive; log-centric branching is cheap because the shared prefix is cached.
Agent coordination: conventional systems depend on explicit messages or A2A protocols; log-centric systems coordinate implicitly through graph reactivity.
Observability: conventional observability is bolted on; in log-centric systems the record is intrinsic.
LLM role: conventional systems make the LLM the loop; log-centric systems treat it as one behavior among many.
Long-running agents: conventional systems hit context-window limits; log-centric systems persist durable graph state over time.
Where This Fits in the Agent Landscape
This model sits between classic orchestration frameworks and full distributed-systems thinking. It borrows from event sourcing, stream processing, Redux-style projection, and actor systems, then applies those ideas to LLM agents in a way most agent stacks still do not.