Loop Engineering Is Just K8s-Style Orchestration
From Watt's governor to Kubernetes to AI agents — the same cybernetic pattern at progressively higher abstraction

Kubernetes solved infrastructure orchestration in 2014 with a single idea: declare what you want, let a control loop reconcile reality toward it. Twelve years later, the AI community is rediscovering the same pattern and calling it "Loop Engineering."
This isn't a loose analogy. It's the same cybernetic architecture — one that predates both K8s and software entirely.
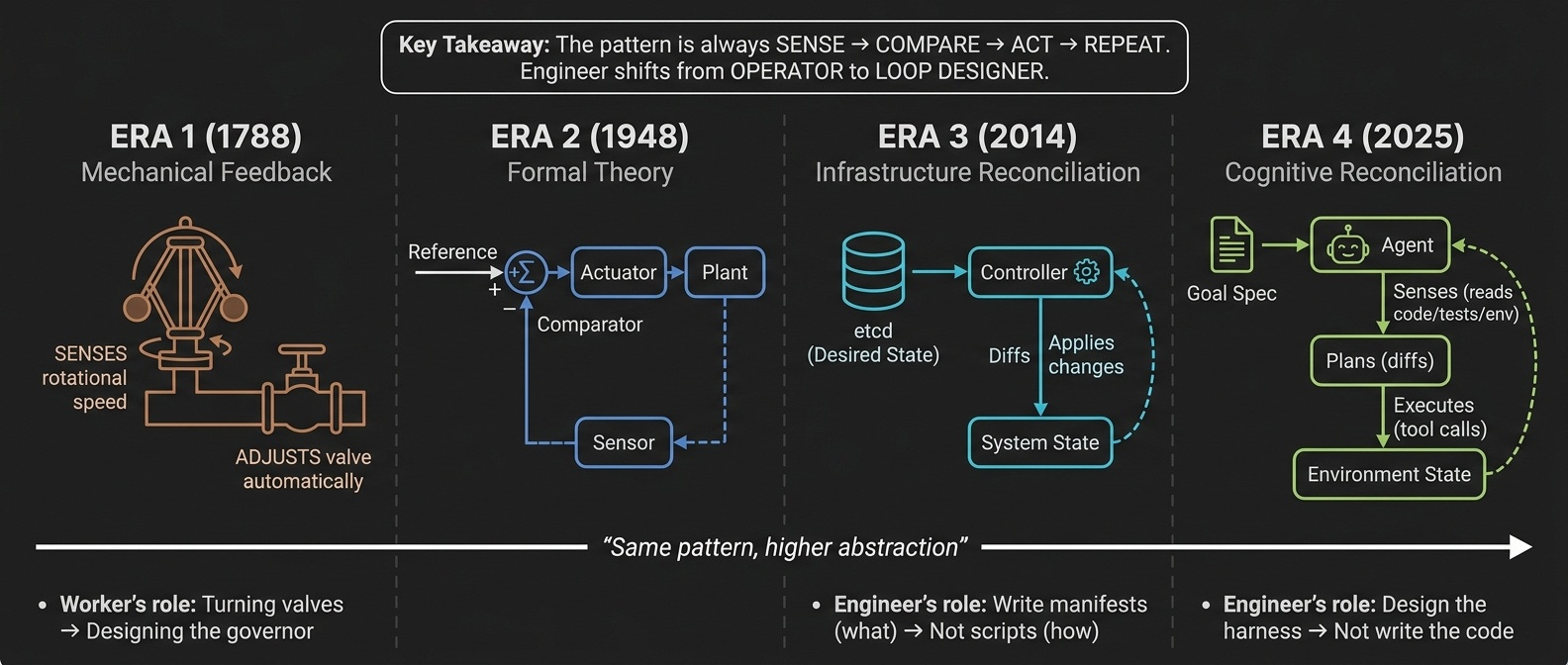
The Pattern Is 250 Years Old
In 1788, James Watt attached a centrifugal governor to a steam engine. Before this, workers manually adjusted valves to stabilize engine speed. The governor changed the job: sense rotational speed, compare to target, adjust the valve, repeat. The worker's role shifted from turning valves to designing and tuning the governor.
In 1948, Norbert Wiener formalized this as cybernetics: any system that senses, compares against a reference signal, and acts to reduce error. Biological, mechanical, or computational — the structure is identical.
In 2014, Kubernetes applied it to infrastructure: declare desired state in YAML, let controllers continuously reconcile reality toward it. The engineer's role shifted from restarting services to writing manifests.
In 2025, the AI community applies it to cognition: declare a goal condition, let an agent loop sense, diff, and act until converged. The engineer's role shifts from writing code to designing the harness.
Each era raises the abstraction. The pattern never changes.
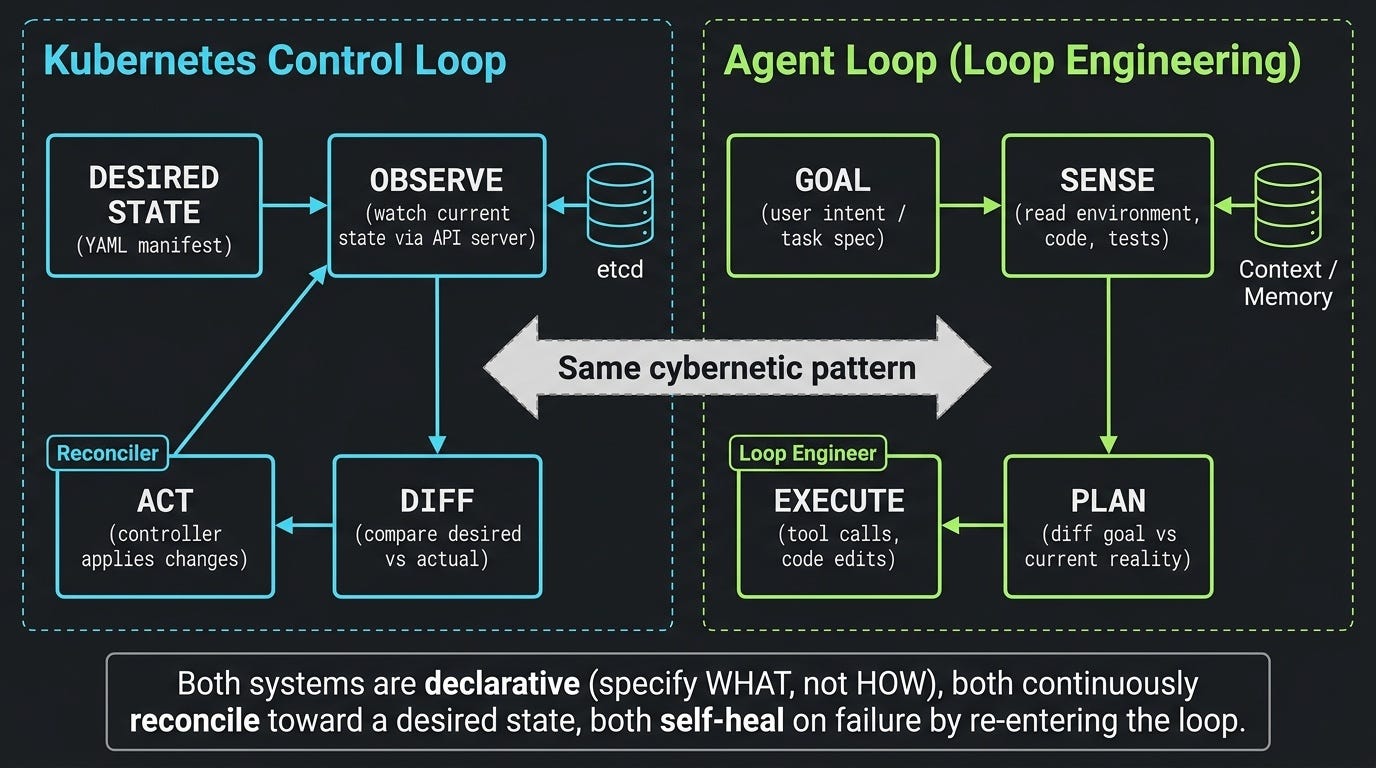
The K8s Reconciliation Pattern
Every Kubernetes controller follows this cycle:
Desired State — a YAML manifest declaring what should exist
Observe — the controller watches current state via the API server
Diff — compare desired vs actual
Act — apply the minimal change to close the gap
Repeat — re-enter the loop, forever
The controller never executes a procedural script. It doesn't know "how" to get from A to B in advance. It only knows how to make the next incremental correction. If a pod dies, the loop notices and recreates it. If config drifts, the loop notices and reconciles. Self-healing is not a feature — it's an emergent property of the loop structure.
There's a reason some of the best AI coders doing agent-loop work since early 2025 are former Kubernetes engineers. They've internalized this pattern at the infrastructure level and simply moved it up a layer.
Loop Engineering Is the Same Architecture
Replace "pod" with "codebase" and "YAML manifest" with "user intent":
Goal — a task spec, acceptance criteria, or desired end-state
Sense — read the environment (code, tests, logs, browser state)
Plan — diff the goal against current reality
Execute — make one incremental change (tool call, code edit, test run)
Repeat — re-enter the loop until the goal condition is met
The agent doesn't follow a pre-planned script. It continuously reconciles toward the goal. If a test fails, the loop notices and fixes. If the environment changes, the loop adapts. Self-healing emerges from the structure, not from special-case error handling.
Design Principles That Transfer
When you see Loop Engineering as K8s-style orchestration, a decade of production learnings transfers directly:
Declarative over imperative. K8s succeeded because operators declare what, not how. The best agent loops work the same way — "all tests pass and the feature matches this spec" beats a 47-step procedural checklist.
Idempotent actions. K8s controllers can safely re-run without side effects. Agent loops need the same property. This is why "edit this file to contain X" works better than "append Y to this file" — the first is convergent, the second drifts on re-execution.
Observe before acting. K8s never assumes state — it reads current reality first. Agents that skip observation (generating code without reading what exists) produce drift, conflicts, and wasted work.
Small diffs, high frequency. A K8s controller doesn't rewrite the entire cluster on each pass. It makes the minimum viable change. Agent loops that generate entire files in one shot are the equivalent of kubectl delete all && kubectl apply — technically works, but fragile and wasteful.
Crash-only design. K8s controllers are designed to be killed and restarted at any point. The loop picks up where it left off because state is externalized. The Fresh-Clone Loop embodies this: clone the repo into a clean environment, follow the README exactly, record every gap, fix the docs, discard the environment, start from a fresh clone. Repeat until a brand-new environment goes from clone to running in one uninterrupted pass. The agent is disposable; the externalized state (the repo, the README) is what persists.
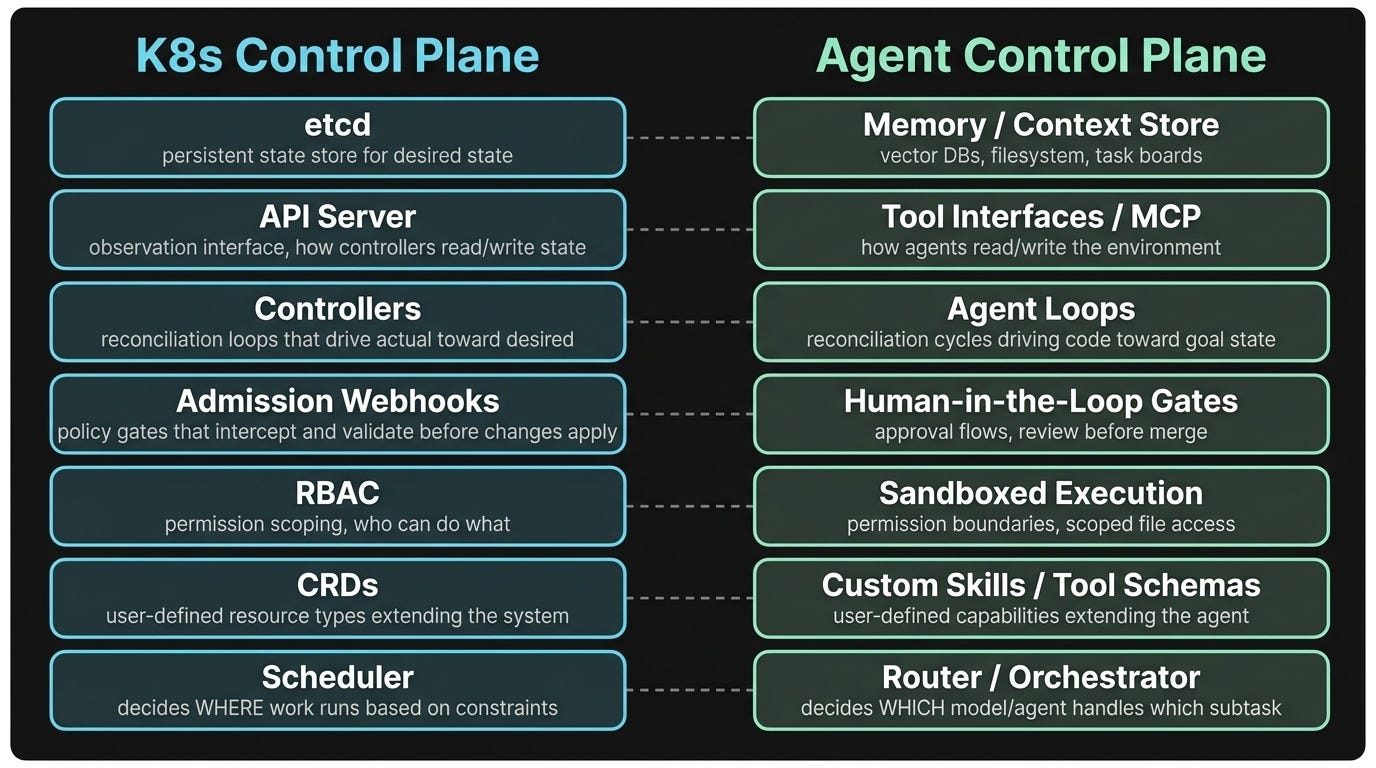
The Control Plane Layer
K8s didn't just give us controllers — it gave us a control plane: etcd for state, the API server for observation, RBAC for access control, admission webhooks for policy gates.
The equivalent is emerging in agent infrastructure:
etcd → context stores, memory systems, task boards, filesystem
API Server → tool interfaces, MCP servers, browser harnesses
Controllers → agent loops, reconciliation cycles
Admission Webhooks → human-in-the-loop gates, approval flows before merge
RBAC → sandboxed execution, permission scoping, scoped file access
CRDs → custom tool schemas, skill definitions
Scheduler → router/orchestrator deciding which model handles which subtask
When someone builds a "software factory" with a taskboard feeding agent loops, they're building a control plane. When someone adds approval gates before an agent can merge code, they're implementing admission webhooks. When someone uses Infrastructure-as-Actors with durable objects managing sandboxes — single-writer, stateful, durable, with scheduled alarms for teardown — they're building the K8s scheduler for AI workloads.
The vocabulary is different. The architecture is identical.
What K8s Teaches Us About Failure Modes
K8s has 10+ years of production learnings about what goes wrong in reconciliation loops. Every one of these failure modes is now appearing in agent loops:
Thrashing. A controller that makes changes too aggressively can oscillate — create 10 pods, kill 8, create 6, kill 4. Agent loops that over-correct on each iteration exhibit the same behavior: fix a test, break two others, fix those, break the original. The fix in both cases: dampen the response, make smaller changes, add backoff.
Stale reads. If the controller reads cached state instead of current state, it acts on lies. Agents that rely on stale context windows (long conversations with outdated code state) make the same mistake. The fix: fresh-clone loops. Start from a clean read of reality every iteration. Don't trust memory.
Infinite reconciliation. Sometimes the desired state is unreachable. A K8s controller trying to schedule a pod with 1TB RAM on 64GB nodes will loop forever. Agent loops given impossible specs do the same. The fix: maximum iteration counts, cost budgets, human-in-the-loop circuit breakers, and "this goal is unreachable" detection.
Conflicting controllers. Two K8s controllers fighting over the same resource create chaos. Two agent loops editing the same file without coordination produce merge conflicts and reverted fixes. The fix: clear ownership boundaries. K8s uses labels and selectors. Agent infrastructure needs task-scoping — one loop owns one bounded resource set.
Unobservable state. A controller that can't read a resource's actual state can't reconcile it. Agents without proper sensing (no test feedback, no browser state, no lint output) can't converge either. The fix: invest in observability before investing in more sophisticated planning.
The Hill Climbing Machine
The pattern extends one level up. Individual agent loops reconcile code toward a goal. But who reconciles the agent itself toward better performance?
The answer is the same architecture, applied recursively:
Encode domain expertise into a v0 agent and ship it
Observe agent behavior — collect traces at scale
Mine traces for failure patterns
Turn failures into evals you can hill-climb against
Improve the agent (harness engineering → fine-tuning → more harness engineering)
Repeat
This is the outer reconciliation loop. The "desired state" is agent performance on your eval suite. The "observation" is trace data. The "action" is agent improvement. It's K8s all the way up.
The Practitioner's Takeaway
If you're building agent loops today:
Study K8s controller patterns. The controller-runtime source is a masterclass in reconciliation design.
Make your loops declarative. Define the exit condition, not the path.
Externalize state aggressively. The agent should be killable and restartable without losing progress.
Add circuit breakers. Maximum iterations, cost budgets, human gates.
Keep actions idempotent. If the loop re-executes a step, nothing should break.
Observe before every action. Never assume the world hasn't changed since your last read.
Dampen corrections. One small change per iteration. Verify before making the next.
Scope ownership. One loop, one bounded resource set. No shared-state free-for-alls.
Loop Engineering isn't new. It's Kubernetes for cognition. It's Wiener's cybernetics for code. It's Watt's governor for software systems. The sooner we recognize that, the sooner we stop reinventing the same failure modes that infrastructure engineers — and mechanical engineers before them — solved decades ago.