The Bitter Lesson of Automated Eval Loops
Automate the labor. Keep the target function human.

The new bitter lesson in AI engineering is not that humans should stay close to every line of code. It is that humans should stay close to the target function.
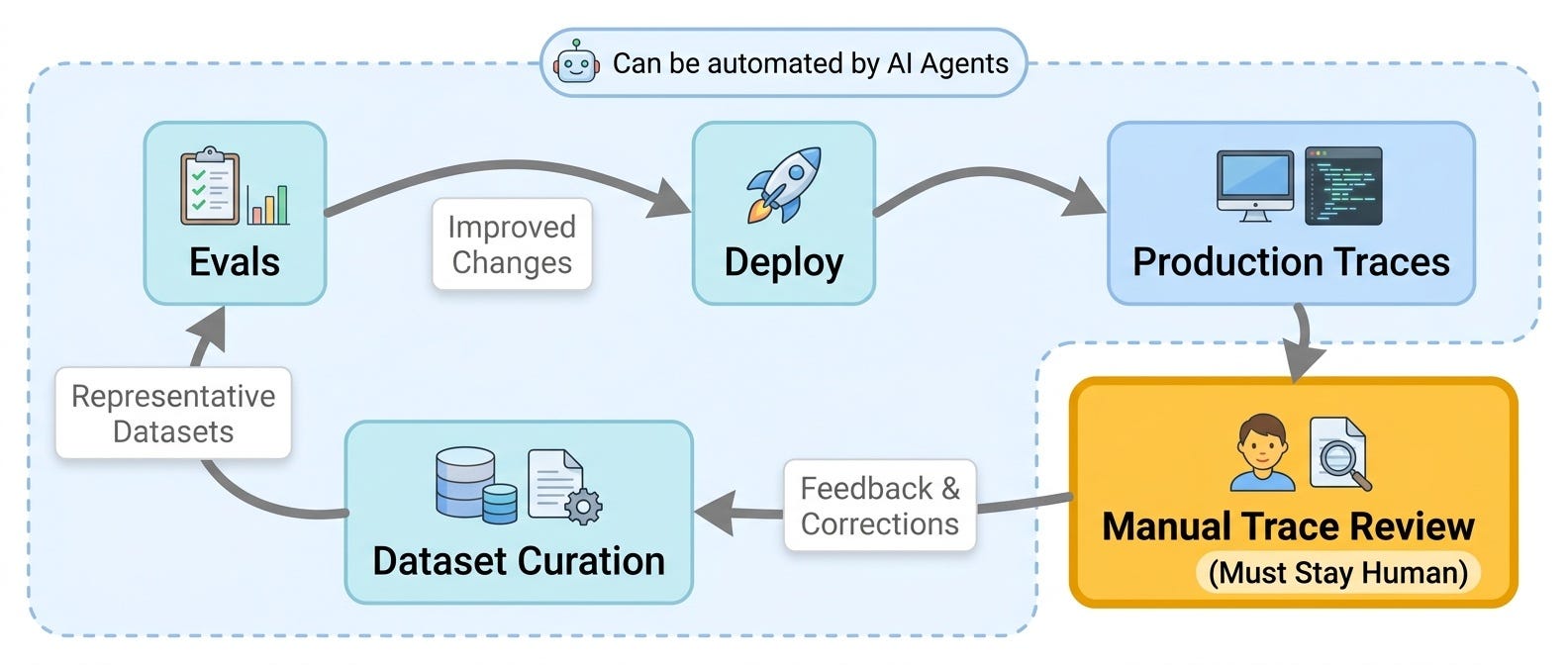
The entire agent evaluation loop is now automatable. Production traces can be collected automatically. Failure clusters can be detected automatically. Representative datasets can be generated automatically. Evals can be run automatically. Candidate changes can be shipped automatically when the metrics are green.
That is the dream version of continual improvement. It is also how agent slop gets manufactured at scale.
Not obviously broken output. Worse: subtly misaligned output. Agents optimizing against an evaluation suite that was correct six weeks ago, before the product changed, before users found new paths through the system, before your own opinion about quality sharpened.
The dashboards stay green. The agent feels worse. Users notice before the eval suite does.
The Loop Can Be Automated. The Target Cannot.
Rich Sutton's bitter lesson was that general methods plus compute beat hand-built human knowledge again and again.
There is a related, inverted lesson forming in agent engineering:
You can automate the labor of evaluation. You cannot safely automate the judgment that defines what the evaluation should mean.
The distinction matters because most agent teams eventually build a loop like this:
collect production traces
sample or cluster failures
generate or refresh datasets
run evals
propose prompt, tool, or routing changes
deploy when the suite improves
Each step is real work. Each step is increasingly easy to give to agents. That part is good.
The failure mode appears when the loop is treated as closed. Once nobody is reading traces with taste and domain context, the system starts optimizing against a stale picture of the world.
A Concrete Failure Pattern
Imagine a commercial insurance carrier using an AI triage agent for first-notice-of-loss intake. The agent reads incoming claim documents, extracts facts, classifies complexity, and routes each claim to the right adjuster pool.
The team has done the responsible engineering work. Traces flow into observability. A CI pipeline runs evals against thousands of historical claims. Routing accuracy stays above 90 percent. Leadership sees a stable metric and moves on.
Then the team closes the loop. Every week an orchestration agent pulls traces, flags low-confidence cases, generates synthetic augmentation data, refreshes the eval suite, and deploys changes when accuracy holds.
For months, nothing looks wrong.
The problem is not in the automation. The automation does exactly what it was asked to do. The problem is that the business changed. The carrier expanded into new states. The new jurisdictions had different litigation patterns, claim timelines, and compliance obligations. The original eval dataset did not represent those cases. The loop kept improving performance against yesterday's understanding.
In production, the agent quietly over-routes a class of coastal commercial property claims to a general adjusting pool instead of a specialist pool. The claims still move. Nothing explodes. But reserves get worse, letters go out inconsistently, and compliance risk accumulates.
No eval catches it because no eval was measuring it.
That is the dangerous version of agent slop: not a hallucination in a demo, but a system that becomes increasingly confident while drifting away from the work it is supposed to do.
Your Mental Model Is The Target Function
Your evaluation suite is not the source of truth. It is a frozen artifact of what you believed mattered when you wrote it.
Your actual target function is your evolving mental model of quality:
what a good answer feels like
which failure modes matter now
where users are getting confused
which edge cases became common
which risks are no longer theoretical
what your product is becoming
That model is contextual. It changes. It includes taste, judgment, domain knowledge, product direction, and the weird texture of real user behavior.
The moment you stop reading traces, you stop updating the model. The agent keeps optimizing anyway.
This is how teams end up measuring the wrong thing with impressive precision.
What Should Stay Human
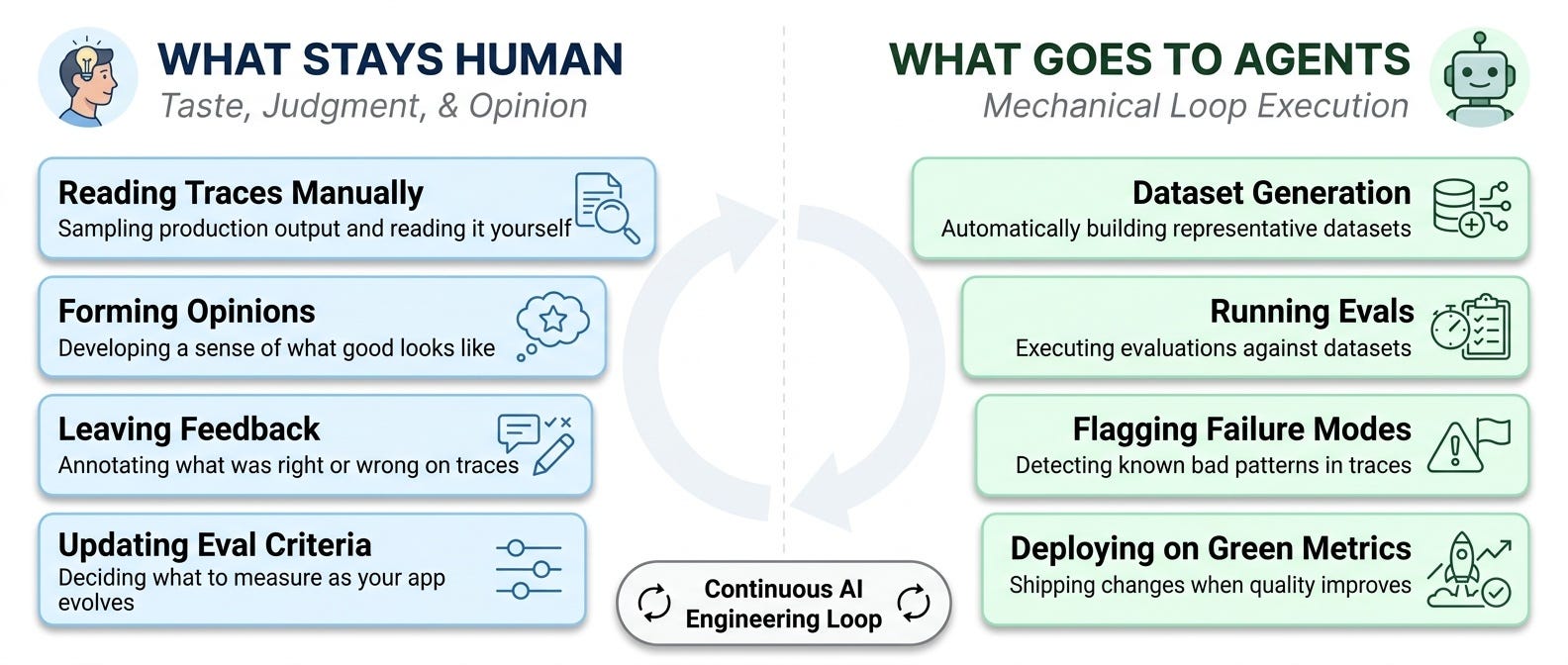
Most of the loop should go to agents. The mechanical work is exactly where agents are useful.
Give agents dataset generation. Give them eval execution. Give them known failure-mode detection. Give them report generation. Give them deployment proposals when metrics improve.
But keep these steps human:
read a random sample of production traces
form opinions about what good looks like
leave feedback in language the system can learn from
update eval criteria as the product, users, and risks change
Do not only inspect the traces your evals flagged. Those are the failures you already knew how to ask for. Random sampling is how you discover the failures your current vocabulary cannot yet name.
The Cheapest Control Is Taste
The practical fix is usually smaller than teams expect.
Put a domain expert, product owner, or senior engineer on a weekly trace-review rotation. Sample a small number of production runs. Read them directly. Mark what feels wrong. Write down why. Turn recurring observations into eval criteria.
That may be two hours a week. It may become 45 minutes once the system learns what kinds of ambiguity to surface.
The point is not manual review as bureaucracy. The point is manual review as gradient.
Your feedback is the signal the rest of the loop needs. Without it, agents can still generate datasets, run evals, and ship changes. They just do it against an increasingly stale definition of quality.
As the easy failures get automated away, what remains is opinionated nuance. That is where the product becomes yours. Two teams can use the same model, the same tracing stack, the same eval runner, and the same deployment pipeline. The difference is the quality of the human taste being injected into the loop.
The Operating Principle
Automate the labor. Do not automate the judgment.
That means:
agents can execute the loop
humans must revise the target
evals should be treated as living product artifacts
trace review should be scheduled work, not emergency work
green metrics should never replace direct contact with production behavior
The more precisely you can articulate what good looks like, the more safely you can hand off. But the act of deciding what good looks like remains load-bearing.
You are the eval. Your taste, your domain judgment, your reading of real traces, and your willingness to update the suite are the target function.
If you automate that away, the optimization has nowhere good to go.